
Orijinal numaraları yayınlayın. Bir sayfayı daha orijinal hale getirmek için en güvenilir araç budur ve en savunulabilir sayılar, bir içerik takvimini beslemek için topladığınız veriler değil, işin kendisinin bir yan ürünüdür.
Eski oyun, bir araba sigortası FinTech'in Yahoo'ya gitmek için yol gezisi araştırması satın alması gibi, ürününüze gevşek bir şekilde bağlı bir anket için bir halkla ilişkiler veya araştırma firmasına ödeme yapmaktı. Bu modası geçmiş. Artık neredeyse her ürün yayınlanmaya değer veriler üretiyor ve bu verileri çekmek hiç bu kadar kolay olmamıştı.
Bir araştırma ekibine ihtiyacınız yok. Sahayı temizleme çıtası sandığınızdan daha düşük.
Birinci taraf verileri: Orijinalliğin en güçlü korelasyonu
On-Page.ai'nin son gelişmeleribilgi kazanımı çalışması50 anahtar kelime ve 10 sektör genelinde 150 ilk 3 Google sayfasını puanlayarak, her birinin sıralama grubunun geri kalanının ötesinde ne kadar katkıda bulunduğunu belirledi ve katkıyı ifadeden ziyade anlama göre 0'dan 100'e kadar derecelendirdi.
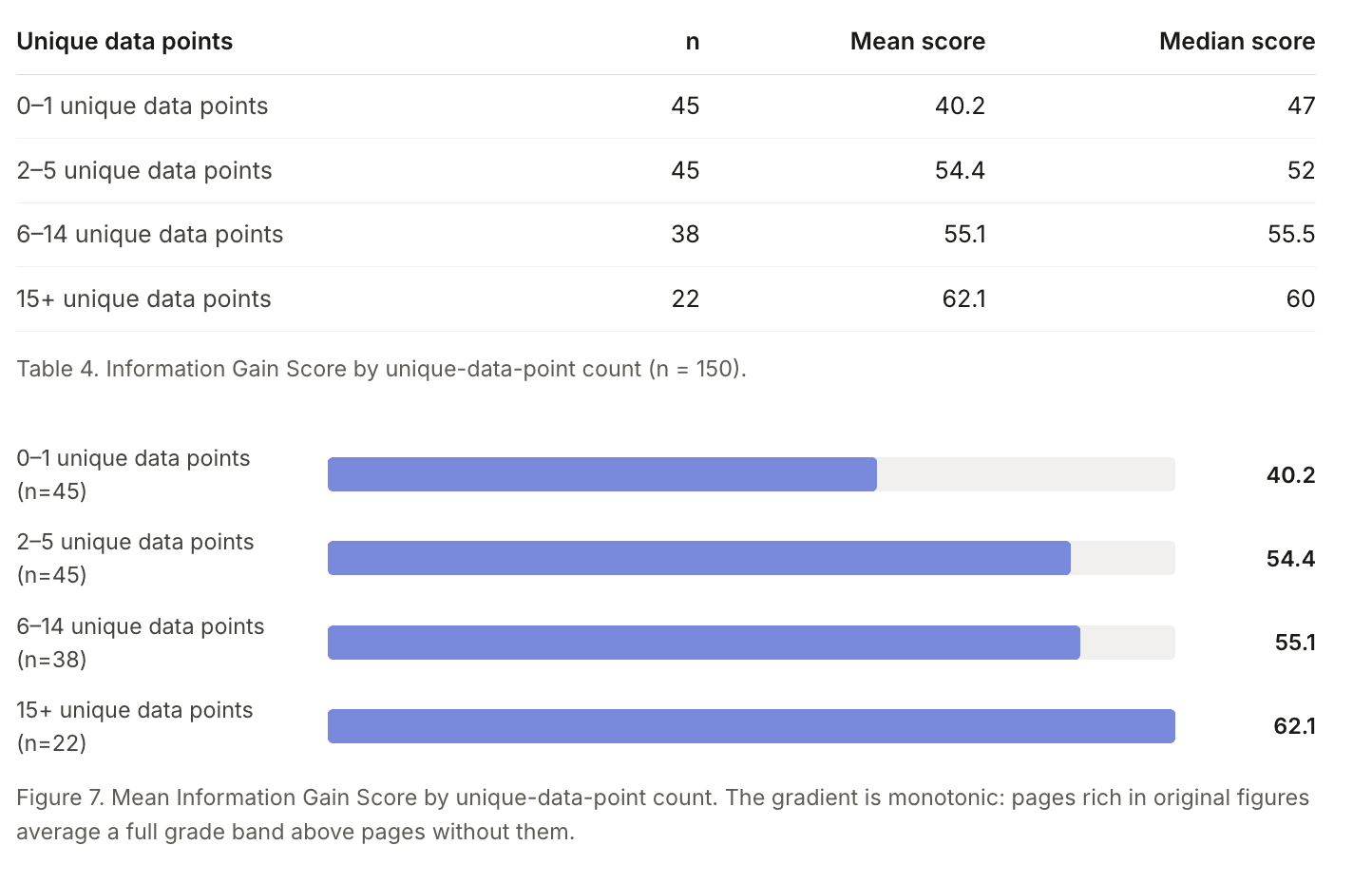
Medyan sayfa 52 puan aldı veorijinal verilercorrelated with that score more than any other page-level trait, including length.
En fazla 1 benzersiz şekle sahip sayfaların ortalama bilgi kazanım puanı 40,2 iken, 15 veya daha fazla olan sayfaların ortalaması 62,1 oldu ve puan aradaki her adımda istikrarlı bir şekilde arttı
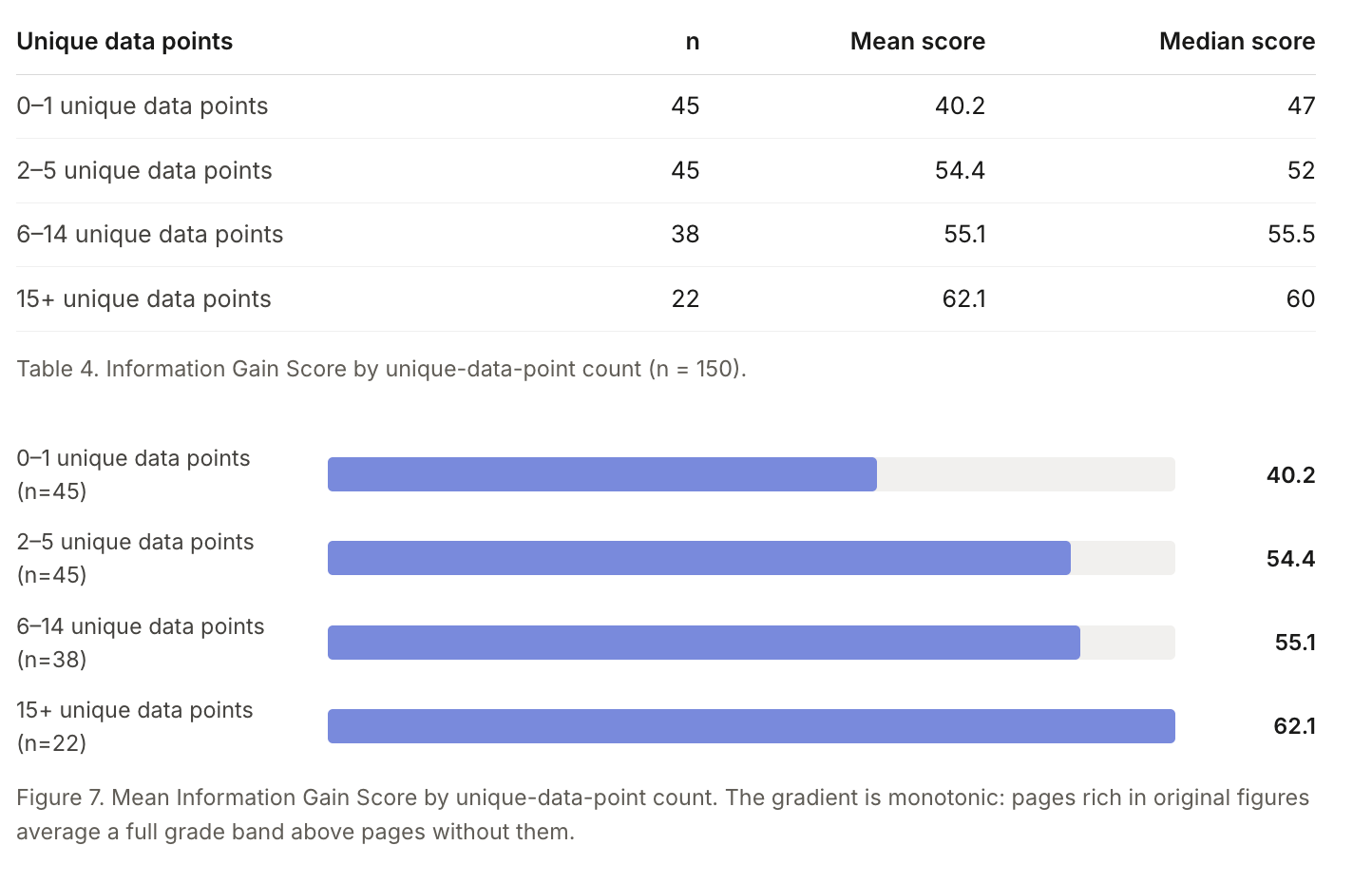
İyi haber, geçilmesi gereken çıta düşük. Çalışma, klasik Google aramasında en çok görünen sayfaları geride bırakmak için çok fazla orijinal kanıt gerekmeyebileceğini buldu: en iyi organik sonuçlarda genellikle ortalama yalnızca 4 benzersiz veri noktası bulunur. 4'ten fazla gerçek orijinal iddia, rakam veya yanıt içeren bir sayfa yayınlayın; bu, giderek daha rekabetçi hale gelen organik görünürlük için kullanabileceğiniz bir kaldıraç daha demektir.
Bu analiz aynı zamanda hemen hemen her aramada, masanın üzerinde çok sayıda yanıtlanmamış sorunun bulunduğunu da ortaya çıkardı. On-Page, analizlerini, her sorgunun arama konusuyla yakından ilişkili olan, çalışma için oluşturulan makul soruların bir örneği olan sentetik okuyucu sorularıyla gerçekleştirdi ve sonuçlar, yeni sayfaların bunları yanıtlaması ve öne çıkması için açık bir kapı gösterdi. (Sana bir şey hatırlattı mı?Sorgu genişletme, belki?)
ChatGPT alıntılarının analizinde de benzer bir bulguya ulaştık:
"10'dan fazla sorgu amacını kapsayan, her zaman yeşil olan tek bir sayfa, AI alıntı erişiminde 10 tek amaçlı sayfadan daha değerlidir. Kapsamlı içeriğin yatırım getirisi önden yüklenir: iyi oluşturulmuş bir sayfa, alıntı erişimini zaman içinde artırır. Uzun kuyruk mevcuttur, ancak sayfaların ilk %5'i, devam eden alıntı etkinliğinden orantısız bir pay alır." –Yapay zekanın kaynaklarını nasıl seçtiğine dair bilim
Aslında markanızın yüksek niyetli yönlendirmelerinin bu amaç için bir yolculuk boyunca izlenmesi gerekir. Bunları, alıcıyı beş aşama boyunca takip eden yolculuklara dönüştürün.Muhakeme Artışı:Problem, Keşif, Karşılaştırma, Doğrulama, Seçim. (Hakkında devamını okudaha doğru AI istem takibiBurada.) Analizdeki bu bulguya karşı yalnızca markanızın rekabetçi kalabileceği bilgi ve uzmanlıkla sayfadaki bu soruları yanıtlayın.
Bulgulardan çıkan ana sonuç: Çoğu sayfa orijinallik konusunda orta düzeydedir, gerçekten orijinal sayfalar azınlıktadır ve göze çarpacak kadar yüksek puanlar elde edilebilir… olağanüstü bir başarı veya başarı olmadan.
Bulgulardaki boşluk mu? Bu çalışma, klasik arama görünürlüğüne ve sıralamalarına odaklanmaktadır (sonuçta, SEO'nun bilgi kazanımı kavramı bir Google patent dilinden doğmuştur). Yapay Zeka alıntılarını veya bahsini dikkate almıyor ve analize Yapay Zeka Modu veya Yapay Zeka Genel Bakışlarının dahil edilmesinden söz edilmiyor.
Uyarı: Birincil kaynak olmak alıntıyı kazanmayabilir
Bu, veri yayınlama tavsiyelerinin atlandığı en özel kısımdır. Herkes orijinal araştırma yayınlayın diyor. Yapay zekanın sayıyı oluşturan markayı mı yoksa onu en okunaklı şekilde sunan sayfayı mı ödüllendirdiğini test eden çok az kişi var.
Gelecek hafta daha fazla veri analizi gelecek ancak geçen yıl Growth Memo'da tamamladığımız analizlerden bildiklerimiz:
- ChatGPT alıntılarını en çok tahmin eden varlık türleri DATE ve NUMBER'dır (başlangıçtan itibaren)Yapay zekanın aslında neyi ödüllendirdiğinin bilimi).Çok alıntı yapılan sayfalar belirli varlıklarla doludur: belirli bir metodoloji, kesin bir istatistik, adlandırılmış bir karşılaştırma. Tescilli bulgularınız bunun yerine alıntı yapılan başka bir kaynak tarafından alınsa bile, bu harici üçüncü taraf otorite sinyallerinin oluşması muhtemeldir.
- Varlık zenginliği ve dengeli duygu önemlidir (Yapay zekanın nasıl dikkat ettiği bilimi).Genel tavsiyeler riskli ve belirsizdir, ancak belirli varlıklar temele dayanır ve doğrulanabilir. Özel veriler üretir, doğrular veya doğrularVevarlık açısından zengin içerik oluşturur. (Düşünün: bir özelliğin neden dolar tasarrufu sağlamak için çalıştığını, müşterilerin daha önce birlikte çalıştıkları rakiplere kıyasla kaç saat tasarruf ettiğini vb.). Verilerinizin analizine ve açıklamasına dengeli bir yaklaşım ekleyin ve kendinize 2'ye 1 taktiğine sahip olun.
Yapay zeka arama çağında birinci taraf verilerinin hayati öneme sahip olduğu hipotezi geçerliyse, özel verilere dayalı içerik yayınlamak gerekli… ancak yeterli değil. Yüksek Lisans çıkarma yapısı (AI arama motorlarının konu için güvendiği sitelerle birlikte), veriler markanıza ait olsa bile alıntıyı kimin alacağına karar verir.
Ne yazık ki, karşılaştırmanızı daha temiz, yanıta hazır bir sayfada yeniden paketleyen bir toplayıcı, araştırmanızın kazandığı alıntıyı toplayabilir. (Gerçek berbattır.)
- Kim kazanır:Tescilli ürün, kullanım veya fiyatlandırma verilerine dayanan, aynı zamanda bunları çıkarım için yapılandıran ve diğer organik marka otoritesi oluşturma oyunlarını göz ardı etmeyen markalar. (Daha fazla bilgi edininTaktikleri aşan bir AI SEO stratejisi nasıl oluşturulur?.)
- Kim kaybeder:Herhangi bir aracın kopyalayabileceği fikir içeriği üreten markalar, kendi sayılarını yüzeye çıkarmak yerine anlatıya gömen birincil kaynakların yanı sıra, site dışı otorite oluşturmanın diğer önemli yollarını da görmezden geliyor.
Bazı sektörlerin veri içeriğini diğerlerinden daha fazla ödüllendirip ödüllendirmediğini henüz bilmiyoruz.bilim serisiBulunan alıntı sinyalleri dikeyden dikeye keskin bir şekilde farklılık gösterir, bu nedenle tek tip bir getiri sürpriz olabilir, ancak veri olmadan bir model iddia etmeyeceğiz.
Çıkarma için veriler nasıl yapılandırılır
Verilere sahip olmak sizi görünürlük mücadelesine sokar. Ancak içeriğinizi nasıl yapılandırdığınız onu kazanan şey olabilir.
18.012 doğrulanmış ChatGPT alıntısını analiz ettikve bir kayak rampası dağılımı buldu: Tüm alıntıların %44,2'si sayfanın ilk %30'undan geliyor. Ortadaki %30-70'lik kesim %31,1 kazanıyor ve uzun bir gönderinin derinliklerine gömülen içeriğin alıntılanma olasılığı kabaca 2,5 kat daha az.
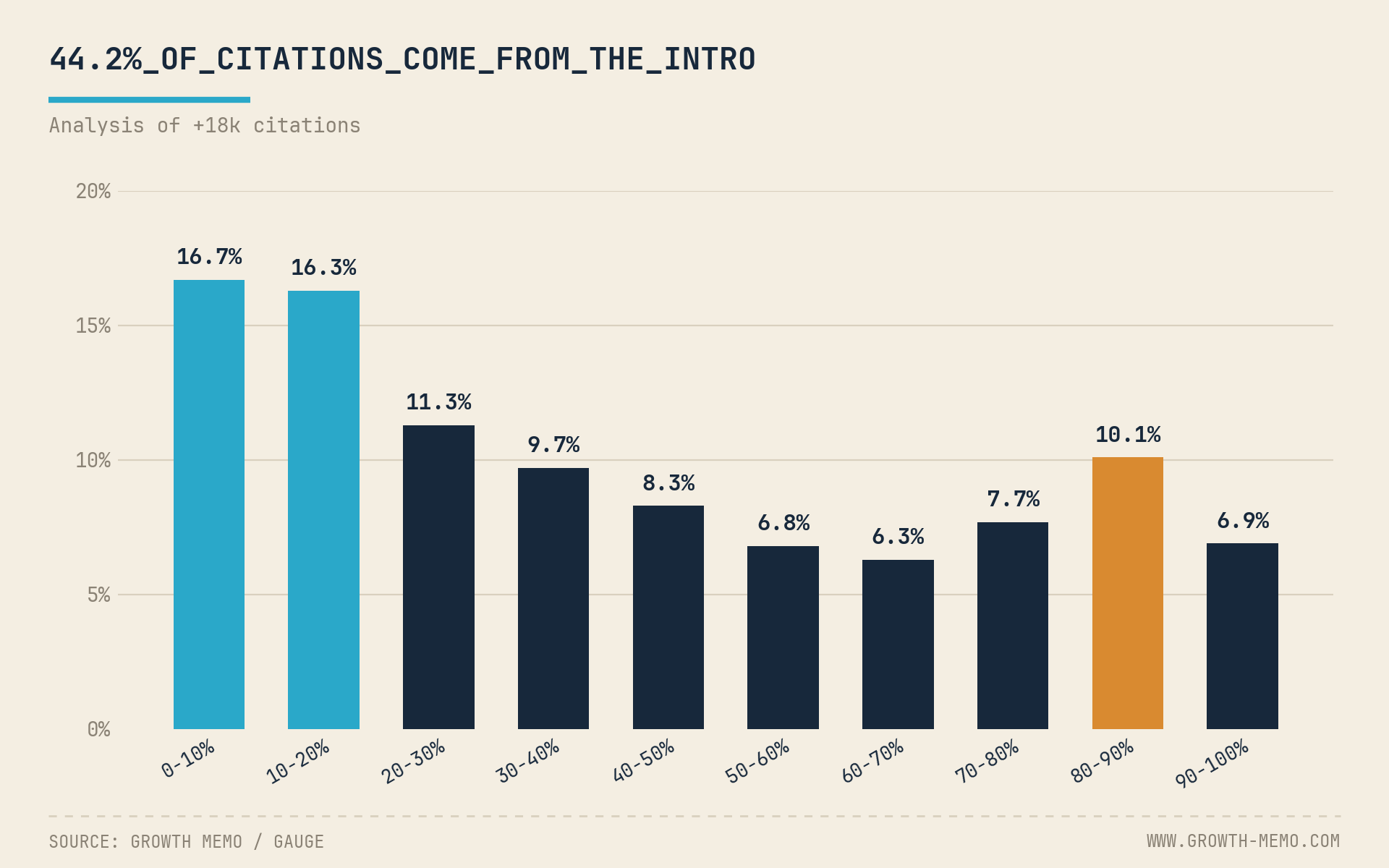
. 7 sektör genelinde takip analizihedefi keskinleştirdi: Bir sayfanın %10-20'lik bandı, yapay zekanın her dikeyde en zor okuduğu yerdir; ilk %10 ise genellikle yapay zekanın atladığı gezinme ve giriş dolgusudur. Herhangi bir sayfanın alt %10'u, sektöre bakılmaksızın alıntıların %2,4-4,4'ünü alır.

Bir veri çalışmasına uygulandığında içeriğinizin yapısı kendi kendine yazar:
- Başlık istatistiğiyle liderlik edin.En güçlü numaranız sayfanın ilk %30'unda, ideal olarak %10-20 bandının başladığı başlık bloğunun hemen sonrasında yer alır. İlk ekranda Sayı → karşılaştırma → çıkarım.
- Metriği hemen tanımlayın.Sayının neyi ölçtüğüne ve kapsadığı nüfusa ilişkin bir cümle. Tanımlanmamış bir istatistiğin güvenle kaldırılması daha zordur
- Metodolojiyi kutulayın.Kısa etiketli bir blokta örnek boyutu, zaman penceresi, toplama yöntemi. Atıf güveni, bir sayıyı alıntılanabilir kılan şeyin bir parçasıdır.
- Her ikincil bulguyu önden yükleyin.Bulgular güce göre sıralanmıştır; en güçlüsü ilk sıradadır. 20 paragraflık anlatım yapısı, makine alıntılarına mal olan, insan tutma modelidir.
- Gerilimi yakından atlayın.Yapay zeka sabırlı bir öğrenci gibi değil, meşgul bir editör gibi okuyor. [kaynak] Nihai kılavuzlar için işe yarayan sonda kazanç yapısı aktif olarak çıkarılmaya karşı çalışır.
Bu yazı ilk olarak yazarın web sitesinde yayınlanmış olup izin alınarak burada yeniden yayınlanmaktadır.