
İçerik stratejistiyseniz buranın sizin bölgeniz olmadığını düşünebilirsiniz. Okumaya devam edin çünkü öyle. Oluşturduğunuz her şey bu beş kapıyı besler ve algoritmaların burada verdiği kararlar, sistemin içeriğinizi alıp almayacağını, içeriği görüntüleyecek kadar ona güvenip güvenmeyeceğini ve tam olarak sattığınız şeyi isteyen kişiye tavsiye edip etmeyeceğini belirler.
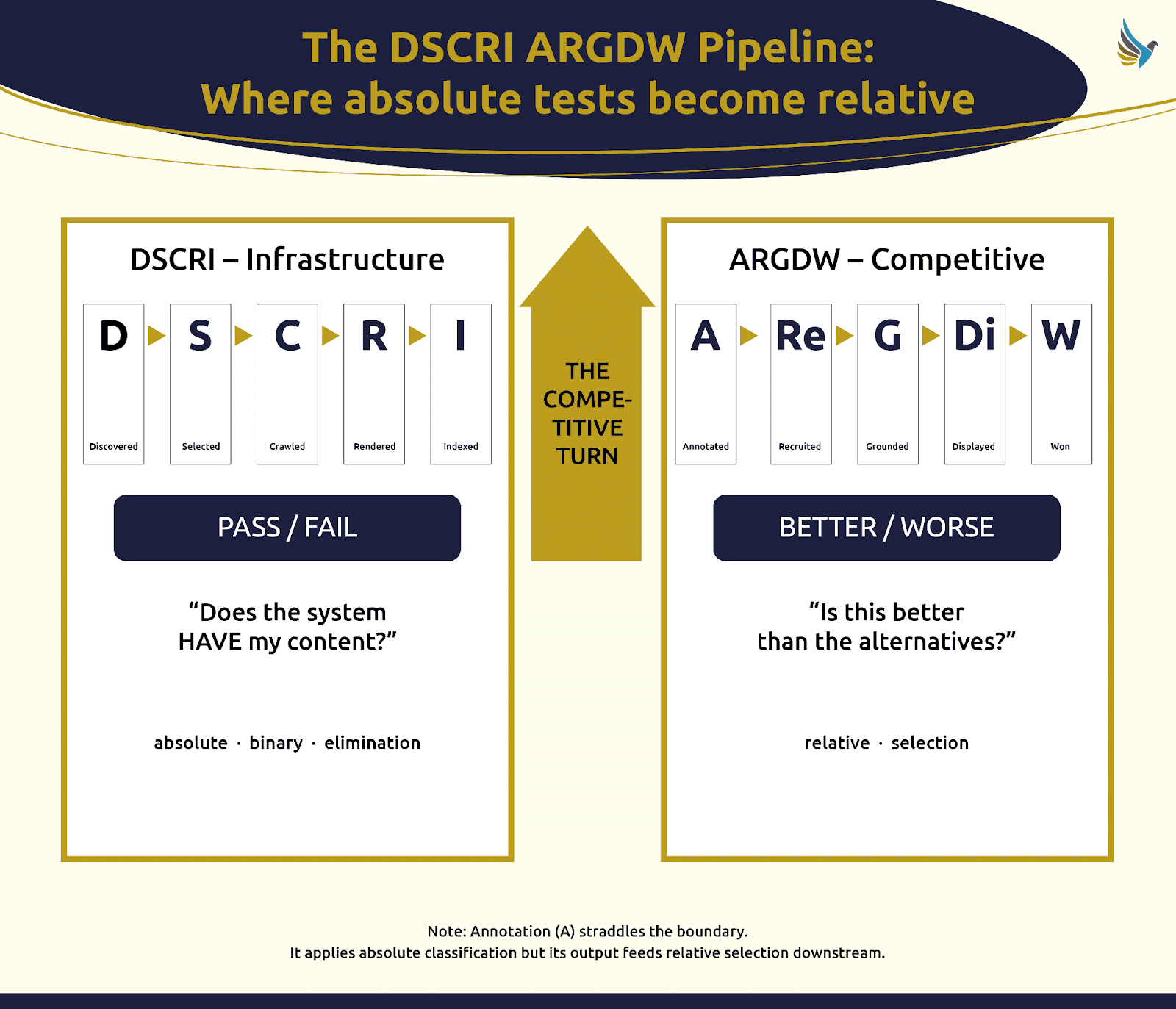
. DSCRI altyapısıaşama ilk beş kapıyı kapsar: indeksleme yoluyla keşif. DSCRI, sistemin içeriğinize sahip olduğu veya sahip olmadığı bir dizi mutlak testtir ve her başarısızlık, rekabet aşamasının devraldığı içeriğin kalitesini düşürür.
Rekabet aşaması, ARGDW (kazanılan aracılığıyla açıklama), bir dizi göreceli testtir. İçeriğinizin yalnızca geçmesi gerekmez. Alternatifleri yenmesi gerekiyor. Mükemmel bir şekilde dizine eklenmiş ancak yetersiz açıklamalara sahip bir sayfa, içeriğini sistemin daha güvenli bir şekilde anladığı bir rakibe kaptırılabilir.
Açıklamalı ancak sistemin bilgi yapılarına asla dahil edilmeyen bir marka, her üç grafikte de görünen bir markaya karşı kaybedebilir. Altyapı aşaması mutlaktır: geçer, durur veya düşer. Rekabet aşaması, Darwin'in "en güçlü olanın hayatta kalması"dır.
DSCRI altyapı aşaması, içeriğinizin bu noktaya gelip gelmeyeceğini belirler. ARGDW rekabet aşaması, yardımcı motorların bunu kullanıp kullanmayacağını belirler.
Bugüne kadar sektör bu beş farklı süreci genel olarak iki kelimeye sığdırdı: "sıralama ve sergileme". Bu sıkıştırma, birkaç ayrı rekabet mekanizmasının görünürlüğünü bulanıklaştırdı. Beşini de anlamak ve optimize etmek, dünyada büyük bir fark yaratacaktır.
Rekabetçi dönüş: Mutlak testlerin göreceli testlere dönüştüğü yer
DSCRI'den ARGDW'ye geçiş, süreçteki en önemli an. Ben buna rekabetçi dönüş diyorum.
Altyapı aşamasında her kapı sıfır toplamlıdır: Sistem bu içeriğe sahip mi, değil mi? Rakipleriniz de aynı sınavla karşı karşıyadır ve ikiniz de geçersiniz ya da başarısız olursunuz. Ancak hayatta kalanların kalitesi ve dönüştürme aslına uygunluğu ileriye dönük farklılıklar yaratır.
DSCRI altyapı kapıları aracılığıyla farklılaşma, saf ve basit ham madde kalitesidir ve rekabete daha iyi ham maddenin girdiği ARGDW aşamasında bir avantaja sahip olursunuz.
Yarışma dönüşünde sorular değişir. Sistem "Bu bende var mı?" diye sormayı bırakır. ve “Bu alternatiflerden daha mı iyi?” diye sormaya başlıyor.
Açıklamadan itibaren her kapı bir karşılaştırmadır. Güven puanınız yalnızca sistemin aynı konu hakkında, aynı sorgu için, aynı amaca hizmet eden diğer tüm içerik parçalarının güven puanlarına göre önemlidir.
İçeriğinizin tamamen bozulmadan kalması için elinizden gelen her şeyi yaptınız. Buradan itibaren motor sizi rakiplerinizle rekabete sokar.

ARGD(W)'de yapısal avantaj olarak çoklu grafik varlığı
Algoritmik üçlü (arama motorları, bilgi grafikleri ve LLM'ler) beş rekabetçi kapıdan dördünde çalışır: ek açıklama, işe alım, temellendirme ve görüntüleme. Kazanılan bu dört kapının ürettiği sonuçtur. Her üç grafikte de yer almak, ARGD genelinde birleşik bir avantaj yaratır ve bu, kazanan marka olma şansınızı büyük ölçüde artırır.
Sistemler sürekli olarak grafikler arasında çapraz referans verir. Varlık grafiğinde onaylanmış niteliklerle mevcut olan, belge grafiğinde destekleyici içeriğe sahip olan ve kavram grafiğinin ilişkilendirme modellerinde görünen bir varlık, her alt kapıda yalnızca bir tanesinde bulunan bir varlığa göre daha yüksek güven alır.
Bu rekabetçi bir matematiktir. Rakibinizin belge grafiği varlığı varsa (aramada sıralanırlar), ancak varlık grafiği varlığı yoksa (bilgi paneli yok, yapılandırılmış varlık verisi yok) ve siz her ikisine de sahipseniz, sistem, iddialarınızı yapılandırılmış gerçeklere göre doğrulayabildiği için içeriğinizi temellendirme konusunda daha yüksek bir güvenle ele alır. Rakibin içeriği yalnızca diğer belgelerle doğrulanabilir; bu, daha fazla belirsizlik, daha fazla belirsizlik, daha düşük güven gibi daha belirsiz bir doğrulama yoludur.

Benim için üç boyutlu yaklaşımın kendini gösterdiği yer burasıdır ve tek grafikli düşünme yapısal bir yükümlülük haline gelir. “SEO” belge grafiği için optimize eder. Varlık optimizasyonu (yapılandırılmış veriler, bilgi paneli ve varlık ana sayfası), varlık grafiği için optimize eder.
Yetkili platformlarda tutarlı, iyi yapılandırılmış metin yazarlığı, kavram grafiğini optimize eder. Çoğu marka bunlardan birine (belki de ikisine) yoğun yatırım yapıyor ve diğerlerini görmezden geliyor. Rekabet kapılarında kazanan markalar, ARGD(W)'de her üç kapıda da rakiplerinden daha güçlü oluyor.

Ek Açıklama: İçeriğinizin 24+ boyutta ne anlama geldiğine karar veren kapı
Ek açıklama, başka kimsenin (Microsoft'un Fabrice Canel'i dışında) hakkında konuştuğunu duymadığım bir şeydir. Ve yine de tüm boru hattının menteşesi olduğu çok açık. İki aşama arasındaki sınırda yer alır: mutlak sınıflandırmayı uygulayan son kapı ve rekabetçi seçilimi besleyen ilk kapı. Yukarı yöndeki her şey (DSCRI'de) ham maddeyi hazırladı. ARGDW'deki her şey sistemin onu ne kadar doğru sınıflandırabildiğine bağlıdır.
İndeksleme kapısında sistem içeriğinizi kendi özel formatında saklar. Ek açıklama, sistemin sakladığı şeyi okuduğu ve ne anlama geldiğine karar verdiği yerdir. Sınıflandırma, en az 24 boyut içeren en az beş kategoride çalışır.
Canel bu prensibi doğruladı ve benim haritaladığım boyutlardan (çok) daha fazla boyut olduğunu doğruladı. Aşağıda, gözlemlenen davranışlardan ve bilgili tahminlerden tanımlayabildiğim kategorilerin yeniden yapılandırılması yer almaktadır.
Canel, Ek Açıklama kapısını 2020'de Bing Serisi kapsamındaki podcast'imde "Bingbot: Keşfetme, Tarama, Çıkarma ve Dizine Ekleme.”
- "İnterneti anlıyoruz, çıkarılan pek çok özelliğe HTML'nin yanı sıra zenginlik sağlıyoruz ve diğer ekiplerin bu verileri alabilmesi, görüntüleyebilmesi ve kullanabilmesi için ek açıklamalar sağlıyoruz."
- "Benim işim bu veritabanına yazmakla bitiyor: yararlı, zengin açıklamalara sahip bilgiler yazmak ve bunu sıralama ekibine işlerini yapmaları için dağıtmak."
Dolayısıyla, ek açıklamanın bir "şey" olduğunu ve diğer tüm algoritmaların bu ek açıklamaları kullanarak parçaları aldığını biliyoruz.
Ek açıklama sınıflandırması, niş başına aynı anda çalışan beş tür uzman modelde çalışır:
- Varlık ve kimlik çözümlemesi (temel kimlik) için bir tane.
- İlişki çıkarma ve amaç yönlendirme için bir tane (seçim filtreleri).
- Talep doğrulaması için bir tane (güven çarpanları).
- Yapısal ve bağımlılık puanlaması için bir tane (çıkarma kalitesi).
- Zamansal, coğrafi ve dil filtrelemesi (geçit denetleyicileri) için bir tane.
Bu beş modelli mimari, gözlemlenen açıklama modellerine ve onaylanmış ilkelere dayanan yeniden yapılandırmamdır. Ek açıklama sistemi, uzmanlardan oluşan bir paneldir ve birleştirilmiş çıktı, her alt geçidin içeriğinizi rakiplerinizle karşılaştırmak için kullandığı puan kartı haline gelir.

Kapı Bekçileri
İçeriğin belirli rekabetçi havuzlara girip girmeyeceğini belirlerler:
- Geçici kapsam (bu güncel mi?).
- Coğrafi kapsam (bu nerede geçerlidir?).
- Dil.
- Varlık çözümü (bu içerik hangi varlığa ait?).
Bir ağ geçidi denetleyicisinin başarısız olması durumunda içerik, kalitesine bakılmaksızın tüm sorgu sınıflarının dışında bırakılır.
Çekirdek kimlik
Bu, içeriğin içeriğini sınıflandırır: mevcut varlıklar, nitelikler, varlıklar arasındaki ilişkiler ve duygu.
Örneğin, sistemin farklı bir Jason Barnard hakkında olarak sınıflandırdığı "Jason Barnard" hakkındaki bir sayfa mükemmel bir altyapıya ve bozuk ek açıklamalara sahiptir. İçerik oradaydı ve sistem onu okudu ancak yanlış çekmeceye dosyaladı.
Seçim filtreleri
Sorgu yönlendirmeyi eklerler: amaç kategorisi, uzmanlık düzeyi, talep yapısı ve işlem yapılabilirlik.
Örneğin, bilgilendirici olarak sınıflandırılan içerik, diğer boyutlarda ne kadar iyi performans gösterirse göstersin, hiçbir zaman işlemsel sorgular için yüzeye çıkmaz.
Ekstraksiyon kalitesi
Düşünmek:
- Yeterlilik (bu parça yararlı olacak kadar içeriyor mu?)
- Bağımlılık (anlamlı olması için diğer parçalara mı dayanıyor?)
- Bağımsız puan (çıkarılıp hala çalışabilir mi?)
- Varlık belirginliği (odak varlık ne kadar merkezidir?)
- Varlık rolü (varlık özne mi, nesne mi, yoksa çevresel bir söz mü?)
Zayıf parçalar rekabet başlamadan önce atılır.
Güven çarpanları
Bunlar sistemin kendi sınıflandırmasına ne kadar güveneceğini belirler: doğrulanabilirlik, kaynak, doğrulama sayısı, özgüllük, kanıt türü, tartışma düzeyi, fikir birliği uyumu ve daha fazlası.
İki içerik parçası diğer tüm boyutlarda aynı şekilde sınıflandırılabilir ve yine de iddialarının ne kadar doğrulanabilir ve doğrulanmış olduğuna bağlı olarak son derece farklı güven puanları alabilir.
Güven konusunda önemli bir husus
Güven, sistemlerin bir içerik parçasını herhangi bir şey için kullanma "cesaretine" sahip olup olmadığını belirleyen bir çarpandır.
Bir zamanlar içerik kraldı. Daha sonra, birkaç yıl önce birçok insanın zihninde bağlam hakim oldu.
Güven, SEO ve AAO'da en önemli faktördür ve her zaman da öyle olmuştur; ancak bunu göremedik.
Kullanıcılarını elde tutmak için arama ve yardımcı motorların mümkün olan en yararlı sonuçları sağlaması gerekir. Onlara, içerik ve bağlam açısından son derece alakalı ve yararlı görünen bir içerik verin, ancak şu veya bu nedenle bu içeriğe kesinlikle güvenmezler ve muhtemelen berbat bir kullanıcı deneyimi sunma korkusuyla bu içeriği kullanmayacaklardır.
Ek açıklama başarısız olursa ne olur (sessizce)
Ek açıklama hataları, görünmez oldukları için işlem hattındaki en tehlikeli hatalardır. İçerik indekslenmiştir. Ancak sistem bunu yanlış sınıflandırırsa, alt kademedeki her rekabetçi karar bu yanlış sınıflandırmayı devralır.
Veritabanımızda bu modeli defalarca gözlemledim: Bir sayfa dizine ekleniyor, arama sonuçlarında görünüyor ve yine de varlık yapay zeka yanıtlarında yanlış temsil ediliyor.
Şunu hayal edin: Web sitenizden bir pasaj/bölüm dizinde yer alıyor, ancak ardışık düzenin DSCRI kısmı nedeniyle güven azaldı ve açıklama aşaması da bozulmuş bir sürüm aldı.
Oluşturma ve indeksleme kapılarındaki yapısal sorunlar indekslemeyi engellemedi ancak bunlar orijinal içeriğin bozulmuş versiyonlarıydı. Bu bozulma, açıklamanın daha az doğru, daha az eksiksiz ve daha az güvenli olmasına neden olur. Bu açıklayıcı zayıflık, ARGDW'de takip edilen her rekabetçi kapıya yayılacaktır.
İçeriğiniz temellendirmeye veya görüntülemeye dahil edildiğinde ve optimum düzeyde olmayan açıklamalarla eklendiğinde içeriğiniz düşük performans gösteriyor demektir. Ek açıklamayı her zaman iyileştirebilirsiniz.
ARGDW'de açıklama kalitesini ölçme
Ek açıklama kalitesi, AI motoru kanalındaki en önemli kapıdır ancak ne yazık ki ek açıklama kalitesini doğrudan ölçemezsiniz. Kullanabileceğiniz her ölçüm, dolaylı bir alt etkidir.
Aşağıda önerdiğim KPI'lar, içeriğinizin nerede dizine eklemeyi temizlediğini ve başarısız ek açıklamayı açıkça gösteren sinyallerdir: motor sayfayı buldu, oluşturdu, dizine ekledi ve ardından ondan yanlış sonuçlar çıkardı.
Bu ayrım önemlidir: asıl sorun "motorun sahip olduğumuz içeriği yanlış okuması" olduğunda "daha fazla içeriğe ihtiyacımız var"dan sakının.
Markanızın SERP'si size algoritmanın tam olarak ne anladığını anlatır
Bu sinyaller yapay zekanın kim olduğunuzu, ne yaptığınızı ve kime hizmet ettiğinizi ne kadar doğru anladığını ortaya koyuyor. Marka SERP'si (ve AI özgeçmişi), markanızın algoritma modelinin bir okumasıdır ve sürekli güncellendiği için onu mükemmel bir KPI haline getirir.
- Marka SERP'si yanlış varlık ilişkilendirmelerini gösteriyor: yanlış rakipler, yanlış kategori, yanlış coğrafya.
- AI özgeçmişi taahhütsüzdür, korunmaktadır veya eksiktir.
- Yapay zeka çıktıları sizi hafife alıyorNEEATTkimlik bilgileri.
- Bilgi panelinde yanlış bilgiler görüntüleniyor.
- Yapay zeka, markanızı bir rakibin çerçeveleme veya kategori dilini kullanarak tanımlar.
- Varlık türü yanlış sınıflandırılmış (kişi kuruluş olarak değerlendiriliyor, ürün hizmet olarak değerlendiriliyor).
- Yapay zeka, markanız ve teklifleriniz hakkındaki temel gerçeklere dayalı soruları riskten korunma olmadan yanıtlayamaz.
Algoritma sizi rekabetçi bir gruba yerleştiremezse tavsiye etmez
Bu sinyaller, sistemin hangi varlıkları karşılaştırılabilir olarak değerlendirdiğini ortaya çıkarır; bu, açıklamaların onları nasıl sınıflandırdığına dair doğrudan bir okumadır. Ek açıklama, varlıkları rekabetçi havuzlara yerleştirir ve markanız ait olduğu karşılaştırma kümelerinde görünmüyorsa motor onu bu havuzun dışında sınıflandırır. Daha iyi içerik bunu düzeltmez. Algoritmanın içeriğinize doğru, ayrıntılı ve güvenli bir şekilde açıklama ekleme yeteneğini geliştirmek.
- Hak kazandığınız durumlarda "[kullanım durumu] için en iyi [ürün]" sonuçlarının bulunmaması.
- “[Rakip] için alternatifler” sonuçlarının bulunmaması.
- Kategoriniz için "[marka A] ile [marka B]" karşılaştırmaları yok.
- Karşılaştırmalarda adlandırılmış ancak yanlış farklılaştırıcılar veya yanlış atfedilmiş özelliklerle.
- Gerçek dünyadaki otorite sinyalleri daha zayıf olan rakiplerin sürekli altında yer alıyor.
Benim için bu sonuncusu en anlamlı olanı. Daha zayıf marka, daha yüksek yerleşim.
Tekrar ediyorum, sorun ne söylediğiniz değil, onu nasıl söylediğiniz ve onu botlar ve algoritmalar için nasıl “paketlediğiniz”dir.
Algoritma sizi istenmeden ortaya çıkaramazsa, niyet anında görünmez olursunuz
Bu sinyaller, kullanıcı sizin var olduğunuzu bilmeden önce yapay zekanın markanızı keşif noktasına yerleştirip yerleştiremeyeceğini ortaya çıkarır. İndekslemenin temizlenmesi, motorun içeriğe sahip olduğu anlamına gelir. Burada başarısız olmak, ek açıklamanın söz konusu içeriği, yardımcı öneriler sağlayan geniş konu sinyallerine bağlamadığı anlamına gelir.
"[Sorunu] nasıl çözerim" yanıtlarında görünen bir marka ile görünmeyen bir marka arasındaki fark, ek açıklamanın içeriği amaca bağlayıp bağlamadığıdır.
- Geçici bir söz olarak bile "[ürününüzün çözdüğü sorunu] nasıl çözerim" yanıtları yok.
- Yapay zeka, icat ettiğiniz veya sahip olduğunuz bir konsepti açıkladığında ortaya çıkmaz.
- Ana konunuz için yapay zeka tarafından oluşturulan özetler, kılavuzlar ve "nereden başlamalı" yanıtları yok.
- Önerilen bir çözüm yerine genel bir örnek olarak adlandırılmıştır.
- Yapay zeka, konu alanınızı uzun uzadıya tartışır ve sizi bir uygulayıcı veya kaynak olarak adlandırmaz.
- Bilgi grafiğinde bulunan ancak yapay zeka platformlarındaki keşif sorgularında görünmeyen varlık.
Optimumun altında ek açıklamayla ödediğiniz üç vergi
Ek açıklama hatasından, dönüşüm hunisinin her katmanında bir tane olmak üzere üç gelir sonucu ortaya çıkar.
- Şüphe vergisi, bir alıcı motorda markanıza ulaştığında ve yapay zeka sunduğunuz ürünün karışık, eksik veya yanlış çerçevelenmiş bir versiyonunu sunduğunda BoFu'ya ödediğiniz vergidir.
- Hayalet vergi, değerlendirme grubuna ait olduğunuzda ve algoritma sizi belirgin bir şekilde içermediğinde MoFu'ya ödediğiniz vergidir.
- Görünmezlik vergisi, izleyici sizi aramayı bilmediğinde ve algoritma sizi tanıtmadığında ToFu'da ödediğiniz vergidir.
Her vergi, ek açıklamanın ne kadar iyi çalışıp çalışmadığının doğrudan okunmasıdır.
Bir SEO/AAO uzmanı olarak müşteriniz veya şirketiniz için bu üç vergiyi azaltma yaklaşımınızı şu şekilde teşhis edebilirsiniz:
- BoFu başarısızlıkları varlık düzeyinde yanlış anlamalara işaret ediyor.
- MoFu başarısızlıkları rekabetçi kohort yanlış sınıflandırmasına işaret ediyor.
- ToFu hataları konu-yetki bağlantısının koptuğuna işaret eder.
Ek açıklama odak noktanız olmalıdır. Benim iddiam, markaların büyük çoğunluğu için, satış hattındaki en büyük geri ödemeye sahip kapının açıklama olacağı yönünde. Çoğu zaman size tavsiyem şu olacaktır: "Başka bir şeye dokunmadan önce bunu düzeltmeye başlayın."
Akademik derinlikteki tam sınıflandırma modeli için bkz.:
- Güven Dayanağı Olarak Ek Açıklama: Yapay Zeka Sistemleri Dijital İçeriği Nasıl Sınıflandırıyor ve Öneri Sonuçlarını Neden Belirliyor?
- Ek Açıklama Basamaklı: Büyük Ölçekli Web İçeriği Sınıflandırmasında Hiyerarşik Model Yönlendirme, Konusal Otorite ve Sayfalar Arası Bağlam Yayılımı
İşe Alım: Rekabetin açıkça ortaya çıktığı evrensel kontrol noktası
İşe alım, sistemin içeriğinizi ilk kez kullandığı yerdir. Sistemin açıklama eklediği her içerik parçası artık sistemin aktif bilgi yapılarına dahil olmak için yarışıyor ve kafa kafaya rekabetin başladığı yer burası.
İçerik ister taramayla, ister anında iletmeyle, yapılandırılmış beslemeyle, MCP'yle veya ortam birikimiyle ulaşsın, üretim hattındaki her giriş modu işe alım sürecinden geçmelidir. Hiçbir içerik, önce işe alınmadan bir kişiye ulaşmaz. İşe alıma “evrensel kontrol noktası” diyebiliriz.
Kritik yapısal gerçek: her biri farklı seçim kriterlerine, farklı güven eşiklerine ve farklı yenileme döngülerine sahip üç ayrı grafiğin toplanmasıdır. Üç grafik modeli benim yeniden yapılandırmamdır.
Temel prensip (farklı özelliklere sahip çoklu bilgi yapıları), topladığımız veriler (Google'ın Bilgi Grafiği, marka arama sonuçları ve Yüksek Lisans çıktılarını kapsayan 25 milyar veri noktası) aracılığıyla algoritmik üçlüdeki davranışları gözlemleyerek doğrulanır.
Varlık grafiği, yapılandırılmış gerçekleri düşük bulanıklıkla saklar - bu varlık kimdir, nitelikleri nelerdir, diğer varlıklarla nasıl ilişkilidir, ikili kenarlar - ve bilgi grafiği varlığı, seçim kriteri olarak varlık belirginliği, yapısal netlik, kaynak otoritesi ve olgusal tutarlılık ile varlık grafiği alımıdır.
Belge grafiği, arama motoru sıralamasının görünür çıktı olduğu ve beklenen sorgularla alaka düzeyinin, içerik kalitesi sinyallerinin, tazeliğin ve çeşitlilik gereksinimlerinin seçimi yönlendirdiği orta derecede bulanık içeriği (sistemin açıklama eklediği ve saklamaya değer olarak değerlendirdiği pasajlar, sayfalar ve parçalar) yönetir.
Kavram grafiği, mekanizma olarak LLM eğitim verileri seçimi ve birincil seçim kriteri olarak doğrulama modelleri ile, yüksek belirsizlikle (topikal ilişkiler, uzmanlık kalıpları, çoklu kaynakların çapraz referansından ortaya çıkan semantik bağlantılar) çıkarsanmış ilişkileri depolayarak tamamen farklı bir düzeyde çalışır.

Aynı içerik bir, iki veya üç grafiğin tümü tarafından toplanabilir. Her grafiğin kendi alım hızı ve kendi çıkış hızı vardır. Ben bunlara üç hız diyorum; bu yıl açıkça formüle ettiğim ancak 10 yıllık marka SERP deneylerinde ampirik olarak gözlemlediğim bir model:
- Arama sonuçları günlük ila haftalıktır.
- Bilgi grafiği güncellemeleri aylıktır.
- LLM güncellemeleri şu anda birkaç aydır (eğitim verilerini manuel olarak yenilemeyi seçtiklerinde).
Topraklama: Sistemin kendi çalışmasını gerçek zamanlı olarak kontrol ettiği yer
İşe alma, içeriğinizi sistemin üç bilgi yapısında depoladı. Temelleme, sistemin bu spesifik sorgu için şu anda içeriğinize güvenip güvenmeyeceğini kontrol ettiği yerdir.
Arama motorları kendi indekslerinden arama yapar. Bilgi grafikleri depolanmış yapılandırılmış gerçeklere hizmet eder. İkisinin de topraklamaya ihtiyacı yok. Yalnızca Yüksek Lisans'larda eski eğitim verileri ile yeni gerçeklik arasında temellendirmeyi gerekli kılan (büyük) uçurum vardır.
Algoritmik üçlünün üç teknolojisi birleşip gerçek zamanlı olarak doğal olarak birlikte çalıştıkça, temellendirme ihtiyacı yavaş yavaş ortadan kalkacak.
Yardımcı bir Motorda LLM baş aktördür. Kullanıcı bir soru sorduğunda veya bir soruna çözüm aradığında LLM kendi cevabına olan güvenini değerlendirir.
Eğer güven yeterliyse yerleşik bilgiden yanıt verir. Güven düşükse, arama dizinine ardışık sorgular gönderir, sonuçları alır, seçilen sayfaları taramak için botlar gönderir ve yeni kanıtlardan bir yanıt sentezler (Perplexity, bunu eylem halinde görmenin en kolay örneğidir - arama sonuçlarını özetleyen bir Yüksek Lisans).
Ama bu çok basit. Aşağıdaki üç topraklama kaynağı modeli, bu yaşam döngüsünün algoritmik üçlü boyunca nasıl işlediğini yeniden yapılandırmamdır.
Sektörün şu anda odaklandığı temel arama motoru şudur: Yüksek Lisans, web dizinini sorgular, belgeleri alır ve cevabı çıkarır. Bu çok yüksek bir tüylenme.
Şimdi şunu ekleyin: Bilgi grafiği basit, hızlı ve ucuz bir aramaya olanak tanır: düşük bulanıklık, ikili kenarlar, yorum gerektirmez ve verilerimiz Google'ın bunu zaten varlık düzeyindeki sorgular için yaptığını gösterir.
Benim iddiam, uzman SLM temelinin üçüncü bir kaynak olarak ortaya çıktığıdır. Bir konu hakkında yeterince tutarlı veri maliyet eşiğini aştığında sistemin o niş için uzmanlaşmış küçük bir dil modeli oluşturduğunu ve bu modelin alan uzmanı doğrulayıcısı haline geldiğini biliyoruz. It would be foolish not to use that as a third grounding base.
Rekabetin etkisi çok büyük. Varlık grafiği varlığına sahip bir marka, sisteme daha az bulanık bir temelleme yolu sağlar. Onsuz bir marka, sistemi yüksek belirsizlik yoluna (belge alma) zorlar; bu da daha fazla yorum, daha fazla belirsizlik ve sonuca daha az güven anlamına gelir. Yapılandırılmış varlık verilerine sahip rakip, daha hızlı ve daha doğru bir şekilde doğrulanır.
Kısacası varlık optimizasyonuna odaklanın çünkü bilgi grafikleri tüm motorlar için en ucuz, en hızlı ve en güvenilir temeldir.
Ekran: Makine güveninin kişiyle buluştuğu yer
İçeriğinize açıklamalar eklendi, bilgi yapılarına dahil edildi ve temellendirme yoluyla doğrulandı. Görüntüleme, AI yardımcı motorunun kişiye ne göstereceğine karar verdiği yerdir (ve halihazırda gerçekleşmekte olan geleceğe bakıldığında, AI yardımcı Aracının neye göre hareket edeceğine karar verdiği yerdir).
Gösterim eşzamanlı üç karardır: format (nasıl sunum yapılacağı), yerleştirme (yanıtın neresinde) ve önem (ne kadar vurgu). Bir markaya yüksek bir güvenle açıklama eklenebilir, işe alınabilir ve temellendirilebilir ve sistem farklı bir format seçtiğinden, rakibi daha belirgin bir şekilde yerleştirdiğinden veya sorgunun tamamen farklı türde bir yanıtı hak ettiğine karar verdiğinden dolayı yine de gösterimde kaybedilebilir.
Bu aslında Bing'in Tüm Sayfa Algoritması ile aynı şeydir. Gary Illyes şaka yollu Google'ın tüm sayfa algoritmasını "sihirli karıştırıcı" olarak adlandırdı. Nathan Chalmers, Bing'in tüm sayfa algoritmasından sorumlu PM'si,2020'deki podcast'imde bunun nasıl çalıştığını açıkladım. Bunun güncelliğini yitirdiğini düşünme hatasına düşmeyin; öyle değil. İlkeler her zamankinden daha alakalı.
UCD ekranda etkinleşir
Anlaşılabilirlik, güvenilirlik ve teslim edilebilirlik hakkında takıntılı bir şekilde konuştuğumu duymuş veya okumuş olabilirsiniz. UCD kesinlikle temeldir çünkü ekranın iç yapısıdır: bu kapıyı üç boyutlu yapan dikey boyut.
Aynı güvenle temellenen aynı içerik, kimin sorduğuna ve neden sorduğuna bağlı olarak farklı şekilde sunulur.
Yüksek güvenle gelen bir kişi (marka adınızı aradı, sizi zaten tanıyor) deneyimleri anlaşılırlık katmanında görüntülenir; burada motor, zaten inandıkları şeyi, yani BOFU'yu doğrulayan güvenilir bir ortak gibi davranır.
Seçenekleri değerlendiren bir kişi - "[kullanım senaryosu] için en iyi [kategori]" diye sordu - güvenilirlik katmanında görüntüleme deneyimi yaşar; burada motor, bir tavsiyeci olarak lehte ve aleyhte kanıtlar sunar; bu da MOFU'dur.
Markanızla ilk kez karşılaşan bir kişi (adınızın yer aldığı geniş bir güncel soru), bunu sistemin sizi tanıttığı teslim edilebilirlik katmanında yani TOFU'da deneyimliyor.
Kullanıcı etkileşimi huninin konumunu ortaya çıkarır. Huni konumu hangi UCD katmanının etkinleşeceğini belirler.
Yalnızca "sıralama" için optimizasyon yapmanın gerçeği kaçırmasının nedeni budur: Görüntüleme, bir liste değil, bağlama duyarlı bir sunumdur ve aynı içerik, kimin sorduğuna bağlı olarak tanıtılabilir, doğrulanabilir veya onaylanabilir.
Ekrandaki çerçeve boşluğu
Sistem anladığını, doğruladığını ve ilgili olduğunu düşündüğü şeyleri sunar. Bununla amaçladığınız konumlandırma arasındaki boşluk, çerçeveleme boşluğudur ve her dönüşüm hunisi aşamasında farklı şekilde çalışır.
- TOFU'da boşluk bilişseldir: Sistem sizin var olduğunuzu biliyor olabilir ancak sizi doğru konularla ilişkilendirmiyor.
- MOFU'da aradaki fark yaratıcıdır: Sistem, kanıtınızı rakiplerinizinkinden farklı kılmak için bir çerçeveye ihtiyaç duyar ve çoğu marka, iddiaları çerçevesiz olarak sunar.
- BOFU'da boşluk alaka düzeyiyle ilgilidir: sistem, iddialarınızı yapılandırılmış kanıtlarla çapraz referanslar ve ya onaylar ya da önlem alır.
Ek açıklamadan sonra çerçeveleme, SEO/AAO bulmacasının en önemli kısmıdır, bu nedenle önümüzdeki makalelerde her ikisinden de çokça bahsedeceğim.
Kazanma: Bir markanın kazandığı ve tüm rakiplerin kaybettiği sıfır toplamlı an
Bu seride şu ana kadar açıkladığım her şey, "kazanılan" kapısında sıfır toplamlı bir noktaya çöküyor. Burada sonuç ikilidir. Kişi (veya temsilci) eylemde bulunur veya bulunmaz. Bir marka dönüşür ve tüm rakipler kaybeder.
Sistem ekranda başkalarından bahsetmiş olabilir, ancak taahhüt anında işlemin yalnızca bir kazananı olabilir.
Rekabetçi bağlamda kazanılan üç karar
Won her zaman her biri farklı rekabet dinamiklerine sahip üç farklı mekanizma aracılığıyla çözümlenir.
Çözüm 1: Kusurlu tıklama
- Yapay zeka, kişinin temellendirme ve sergileme konusundaki düşüncesini etkiler, ancak kişi bağımsız olarak karar verir: Motorun sunduğu çeşitli seçeneklerden birini seçer, mağazaya girer veya telefonla rezervasyon yapar.
- Bu, Google'ın "gerçeğin sıfır anı" olarak adlandırdığı, rekabetçi savaşın sergilendiği, motorun insanı etkilediği, ancak kişinin yaptığı aktif seçimin hala büyük ölçüde "onlar" olduğu yerdir.
Çözüm 2: Mükemmel tıklama
- Yapay zeka bir marka önerir ve kişi onu alır. Bu, sıfır toplamlı an dediğim doğal bir sonraki adımdır.
- Bu, motorun amaç, bağlam ve hazır olma durumuna göre filtrelediği, tek bir yanıt sunduğu ve kişinin dönüştüğü yapay zeka arayüzünde tetiklenir.
Çözüm 3: Aracı tıklama
- Yapay zeka aracısı, kişi adına özerk bir şekilde hareket eder. Karar noktasında hiç kimse yok, alıcının temsilcisi ile markanın eylem uç noktası arasında bir API anlaşması var.
- Rekabetçi mücadele tamamen motorun içinde gerçekleşti: Hangi marka en yüksek birikmiş güvene, en güçlü temel kanıta ve işlevsel bir işlem uç noktasına sahipse, o kazanır. Kişi seçmiyor. Sistem onlara göre seçim yapıyor.
Yörünge en eskiden en yeniye doğru ilerliyor: Çözüm 1 2025'in sonlarına kadar baskındı, Çözüm 2 devraldı ve Çözüm 3 2026'nın başlarında büyük ilgi gördü. Stripe ve Cloudflare işlem ve kimlik raylarını döşüyor. Visa ve Mastercard finansal otorizasyon altyapısını oluşturuyor.
Anthropic'in MCP'si koordinasyon katmanını sağlıyor. Google'ın UCP ve A2A'sı, temsilcilerin tüketici ticareti yolculuğunun tamamında nasıl iletişim kurduğunu tanımlıyor. Apple, istedikleri anda bir milyar cihazda sorunsuz çalışmasını sağlayacak kapalı döngü altyapısına sahiptir.
Microsoft, Copilot aracılığıyla kurumsal ve hükümet katmanını yerinden edilmesi son derece zor olacak bir şekilde kilitliyor. Tek bir şirket Çözüm 3'ü etkinleştirmez; ancak hepsi birlikte bunu kaçınılmaz kılar.
Beş ARGDW kapısında rekabetçi artış
Rekabetin yoğunluğu her kapıda artıyor; aşamalı bir daralma, alanın her aşamada daraldığı Darwinci bir huni. Daraltma modeli, veri tabanımızda gözlemlenen sonuçlara dayanan modelimdir. Temel prensip (rekabetçi seçim aşağı yönde yoğunlaşır) herhangi bir sıralı yolluk sistemi için yapısaldır.

- Algoritmaların puan kartları oluşturduğu ve rakiplerinize göre sınıflandırmanızın alt konumdaki konumlandırmayı belirlediği ek açıklamada alan büyüktür.
- İşe alım eleme turunu belirliyor: Sistemin bilgi yapılarına birden fazla marka giriyor, ancak hepsi değil ve seçim kriterleri zaten çoklu grafiğin varlığını destekliyor.
- Güven gereklilikleri sıkılaştıkça topraklama, kısa listeyi daraltır; sistem, herkesi değil, kontrol edilmeye değer adayları doğrular.
- Gösterim, genellikle destekleyici alternatiflerle birlikte tek bir birincil öneri olan finalistlere indirgenir.
- Kazanılan ikili sonuçtur. Ya kollarınızı açarak karşıladığınız ya da korktuğunuz sıfır toplamlı an.
ARGDW: Göreceli testler. Skor tabelası açık.
Beş kapı. Beş göreceli test. ARGDW'deki rekabetçi arızaların teşhis edilmesi, DSCRI'deki altyapı arızalarından önemli ölçüde daha zordur çünkü düzeltme, teknik olmaktan ziyade rekabetçi konumlandırmadır.
- Ek açıklama hataları, sistemin içeriğinizin ne olduğunu veya kime ait olduğunu yanlış sınıflandırdığı anlamına gelir; varlık netliği için yazın, iddiaları açık kanıtlarla yapılandırın ve sistemin tahmin etmesini beklemek yerine şema işaretlemesini kullanın.
- İşe alma başarısızlıkları giderek sizin tek bir grafikte yer almanız anlamına gelirken rakiplerinizin iki veya üç tane varlığı var: koordineli bir program olarak varlık grafiği varlığı (yapılandırılmış veriler, bilgi paneli, varlık ana sayfası), belge grafiği varlığı (içerik kalitesi, konu kapsamı) ve kavram grafiği varlığı (yetkili platformlar arasında tutarlı yayınlama).
- Topraklama hataları, sistemin sizi yüksek bulanıklık yolunda doğruladığı anlamına gelir; düşük bulanıklık doğrulaması için yapılandırılmış varlık verileri ve arama adımı olmadan gerçek zamanlı topraklamaya ihtiyacınız varsa MCP uç noktaları sağlayın.
- Görüntüleme hataları, çerçeveleme boşluğunun görünür kapının üç katmanında size maliyet getirdiği anlamına gelir; tüm yukarı akış sorunlarını düzelttiğinizi varsayarak, o zaman her UCD katmanındaki çerçeveleme boşluğunu kapatmak, yapay zeka motorlarında görünürlük kazanma yolunuz olacaktır.
- Kazanılan başarısızlıklar, çözüm mekanizmasının mevcut olmadığı anlamına gelir - Çözüm 1, sıralamanızı gerektirir (2024'e kadar yeterince iyi), Çözüm 2, pazarınıza hakim olmanızı gerektirir (2026'da yeterince iyi) ve Çözüm 3, bir yetki çerçevesi ve eylem uç noktası gerektirir (2027'den itibaren gereklidir).
10 kapılı yapay zeka motoru hattını kurduktan sonra sırada ne var?
Bu makale serisinin amacı size DSCRI altyapı aşamasına yönelik taktik kitabını ve ARGDW rekabet aşamasına yönelik stratejiyi vermektir. Bu 10 kapılı yapay zeka motoru hattı, yardımcı motorlar ve aracılar için optimizasyonu yönetilebilir parçalara ayırır.
Her kapı kendi başına yönetilebilir. Ve her kapının göreceli önemi artık sizin için açıktır (umarım). Bu makale serisinin geri kalanında, her kapıdaki ana sorunlara, her birini ayrı ayrı (ve kolektif bütünün parçası olarak) yönetmenize yardımcı olacak çözümler sunacağım.
Bir kenara:Şu ana kadar bu seriyle ilgili Microsoft'tan aldığım geri bildirimler (teşekkür ederim Navah Hopkins) bana Chalmers'ın 2020'de Arama'da Darwinizm hakkında söylediği bir şeyi hatırlattı.
- “... senin özetlediğin kadar mekanik değil.”-Nathan Chalmers
Açıklamalarım çoğu zaman gerçeklikten daha mutlak ve mekaniktir. Bu çok haklı bir nokta. Ancak bu durumda gerçeklik yönetilemeyecek kadar incelikli olur ve incelikler netlik eksikliğine yol açar ve çoğu zaman insanları eyleme geçirilebilir sonraki adımları belirlemekte zorlandıkları ölçüde felç eder. Yararlı olmak istiyorum.
Bu evrimi SEO'dan AAO'ya adım adım atmamızı öneriyorum. Son 10 yılı aşkın süredir, "duruma göre değişir" demekten kaçınmak için her zaman elimden gelenin en iyisini yaptım.
İnsanlar genellikle uzman olmanın 10.000 saat sürdüğünü söylüyor. Burada sunulan çerçeve, verileri analiz etmek, deneyler yapmak, bu sistemleri oluşturan mühendislerle birlikte çalışmak ve algoritmalar, altyapı ve KPI'lar geliştirmek için harcanan onbinlerce saatin sonucudur.
Amaç basit: sinir bozucu "duruma göre değişir" yanıtlarının sayısını azaltmak ve eyleme geçirilebilir sonraki adımları belirlemek için net bir taslak sağlamak.
Bu, AI otorite serimin beşinci parçası.
- İlki, “Rand Fishkin yapay zeka önerilerinin tutarsız olduğunu kanıtladı - işte bunun nedeni ve nasıl düzeltileceği”, basamaklı bir güven getirdi.
- İkincisi, “AAO: Neden yardımcı temsilci optimizasyonu SEO'nun bir sonraki evrimidir?disiplinin adını verdi.
- Üçüncüsü, “Yapay zeka motoru hattı: Tavsiyeyi kazanıp kazanmayacağınıza karar veren 10 kapı” tüm boru hattının haritasını çıkardı.
- Dördüncüsü, “Tarama, oluşturma ve dizine eklemenin arkasındaki beş altyapı kapısı”ilk beş kapıdan geçti.
- Sırada: "Markanın dijital ayak izi: Varlık ana sayfası, varlık ana sayfası web sitesi ve içerik haritası."



