
Yapay zeka araması yalnızca sonuçları çevirmez veya yerelleştirmez. İlk etapta hangi kaynakların, kurumların ve gerçeklik versiyonlarının ortaya çıkacağına karar verir.
Katalonya bu sistem için faydalı bir stres testi sunuyor. İki dil aynı coğrafyayı paylaşıyor, bu da erişim kalıplarının fark edilmesini kolaylaştırıyor.
Google AI Genel Bakış ve ChatGPT'de aynı sorgular Katalanca ve İspanyolca olarak çalıştırıldığında, farklılıklar ifadelerin çok ötesine geçiyor ve çok dilli bölgelerin çok ötesine uzanan daha geniş sorunları ortaya çıkarıyor.
Yapay zeka araması için bir stres testi olarak Katalonya
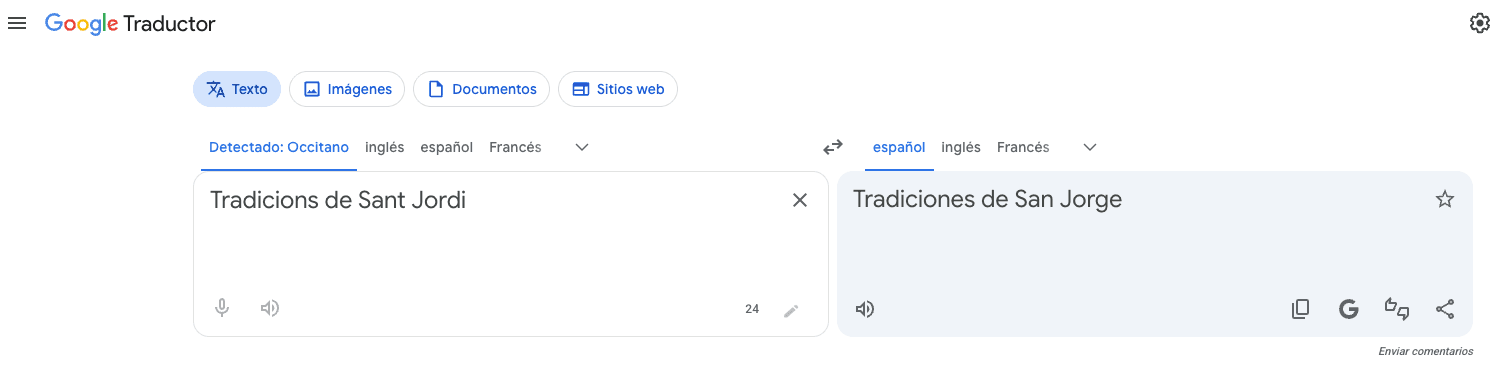
Eğer ararsanız bunu biliyor muydunuz?Sant Jordi'nin Gelenekleri — Aziz George Gelenekleri, Katalanca yazılmıştır — Google Çeviri kaynak dili Oksitanca olarak mı tanımlayacak?
Muhtemelen hayır. Katalanca konuşanların çoğu da bunu bilmiyor, bunun nedeni kısmen Translate'in dil tahmininin tamamen yanlış olmaması: Katalanca ve Oksitanca ortak bir Romantizm soyunu paylaşıyor ve bazı sınıflandırma sistemleri bunları bir arada gruplandırıyor.
Cevap teknik olarak savunulabilir. Bu aynı zamanda istatistiksel olarak tuhaf bir çağrı ve altyapıda çok daha büyük bir soruna işaret eden türden küçük bir anekdot.
 Google Çeviri, "Tradicions de Sant Jordi" girişini ve "Tradiciones de San Jorge" çıktısını içeren "Detectado: Occitano"yu gösteriyor
Google Çeviri, "Tradicions de Sant Jordi" girişini ve "Tradiciones de San Jorge" çıktısını içeren "Detectado: Occitano"yu gösteriyor
Oksitanca'nın çoğunluğu güney Fransa'da olmak üzere yaklaşık 200.000 kişi tarafından konuşulmaktadır. Katalanca yaklaşık 9 milyon kişi tarafından konuşulmaktadır ve Avrupa'nın en zengin bölgelerinden biri olan ve Google'ın 20 yılı aşkın süredir faaliyet gösterdiği bir şehre ev sahipliği yapan Katalonya'nın ortak resmi dilidir.
Google'ın çeviri ürünü, Barselona'daki bir IP'den sorulduğunda, daha makul kaynak dilin, başka bir ülkede çok daha az konuşmacıya sahip olan dil olduğuna karar verir. Çevir ve oluşturSant Jordiİspanyolcaya şu şekildeSan Jorge- Katalonya'nın koruyucu azizinin özel adının Kastilyalaştırılması, ilk etapta tercüme edilmesi gerekmeyen bir isim.
Bu tek Çeviri tuhaflığı anekdot niteliğindedir. İşaret ettiği şey değil. Bu, yıllardır Google'ın altyapısında yaşayan bir dil tanımlama sorunudur ve Google'ın kendisi de bu sorunu çözmüştür.bunu açıkça kabul ettiBu ekibin büyük bir
Ocak 2023'te şirketin Arama İrtibat hesabı, Katalanca konuşan kullanıcılardan gelen, Katalanca sonuçların İspanyolca sonuçlar lehine düşürülmesiyle ilgili bir dizi şikayete yanıt verdi. Google, sorunu "öncelik" olarak nitelendirdi ve araştırmaya devam edeceğini taahhüt etti. Hatta bu açıklama Katalanca dilinde de yayınlandı; etkilenen kitlenin gerçek ve doğrudan yanıt verilmesini gerektirecek kadar büyük olduğunun zımni bir kabulü.
Google daha sonra o yıl klasik SERP'lerde Katalanca görünürlüğünü ölçülebilir şekilde artıran güncellemeler yayınladı. Ancak altta yatan dil tanımlama katmanı hiçbir zaman yapısal olarak onarılmadı. Bugün Katalanca konuşan bir kişi, Google'ın Yapay Zeka Genel Bakışı'nın Katalanca dilindeki bir sorguya İspanyolca yanıt vermesini izlediğinde, bu yeni bir hata değil. Bu, artık onu yayan bir sentez katmanının altında oturan eski bir böcek.
Yapay zeka araması geldiğinde, sorgu dilinin ilk etapta güvenilmez olduğu varsayımını devralır. Bugün Katalancayı İspanyolcaya düzleştiren geri getirme hattı, yüzeydeki dilin asla değişmediği pazarlarda, değiştirilmiş biçimlerde alt-ulusal yargı bağlamını düzleştirecek olan boru hattının aynısıdır.
Son birkaç ayı belgelemekle geçirdimAI araması nasıl çöker?İspanyol pazarları — İspanyolca konuşulan 20'den fazla ülkeyi tedavi ediyoruz tek bir istatistiksel varsayılan olarak. Bu çalışmanın sonuçları ciddi ama en azından coğrafya temiz: İspanya bir ülke, Meksika başka bir ülke; model onları birbirinden ayırmayı başaramıyor.
Katalonya'da olup bitenler daha aydınlatıcı çünkü coğrafya değişmiyor. İki dil aynı bölgeyi paylaşıyor ve sistem, dilleri tanımlayabildiğinde iki paralel gerçeklik üretiyor.
Çok dilli bölgeler, erişime ilişkin mimari varsayılanların görünür hale geldiği yerdir, çünkü bu bölgelerdeki kullanıcılar dilleri değiştirebilir ve sistemin anlamı, otoriteyi ve hatta bazen yanıtın dilini yeniden atamasını izleyebilir.
Aynı kusurlar, görünüşte tek dilli görünen piyasalarda farklı biçimlerde ve farklı hafifletmelerle ortaya çıkacaktır. Katalonya öncü bir göstergedir.

Bunu nasıl test ettim
Tanımlamak üzere olduğum modeller, son on yılda Katalanca SEO üzerinde çalışan herhangi bir uygulayıcıya tanıdık gelecektir; benim kendi deneyimim ve benzer koşullar altında çalışan birçok meslektaşımın deneyimi.
Katalanca anahtar kelime araştırması yapmayı deneyen herkes, Google Anahtar Kelime Planlayıcı'nın, Katalanca konuşanların günlük sorguladığı terimler için esas olarak sıfır hacim rapor ettiğini veya İspanyolca dil verileriyle açıkça karıştırılmış ve temiz bir şekilde kullanılması imkansız olan hacimlerin geri dönüş hacimlerini rapor ettiğini izlemiştir.
Çok dilli siteler işleten herkes, standart araçların açıklayamadığı nedenlerle Katalanca versiyonlarının İspanyolca olanlardan daha düşük performans gösterdiğini görmüştür. Aşağıda anlattığım küçük deney, iddianın temeli değil, bu daha geniş ve iyi bilinen sistemik durumun spesifik, tekrarlanabilir bir örneğidir.
Kurulum kasıtlı olarak basitti. Barselona metropol bölgesindeki bir konut IP'sinden, iki yüzeyde Katalanca ve İspanyolca dillerinde bir dizi eşleştirilmiş sorgu çalıştırdım:
- ChatGPT (çıkış yapıldı, yeni oturum, kişiselleştirme yok).
- Sistem bir tane oluşturmayı seçtiğinde AI Genel Bakış özelliği etkinleştirilmiş Google web araması. (Google her sorgu için bir Genel Bakış oluşturmaz; kendisi de dikkate değer bir sinyaldir.)
Oturumlar gizli modda yürütüldü. Gördüğümün istikrarlı bir kalıp mı yoksa tek oturumluk bir yapı mı olduğunu test etmek için sorguları yaklaşık bir hafta arayla iki kez çalıştırdım. Her iki tarih de belgelenmiştir. Ekran görüntüleri, konum altbilgileri görünür şekilde mevcuttur.
Her biri geri alma yığınının farklı bir katmanını test etmek için tasarlanmış beş amaç çifti seçtim:
- Walker ve Timoneda'nın çalışmalarında akademik emsali olduğu için seçilen Katalan bağımsızlığı hakkında politik açıdan yüklü gerçeklere dayalı bir sorgu2025 araştırması(Siyaset Bilimi Bölümü, Purdue Üniversitesi) dil koşullu Yüksek Lisans çıktısı, Cambridge University Press'te yayınlandıSiyaset Bilimi Araştırmaları ve Yöntemleri. Yöntemlerinin Barselona IP'sinde kopyalanması, bölüme editoryal kapak sağlıyor.
- Serbest çalışanlara yönelik yerel muhasebeciler hakkında işlemsel bir ticari sorgu; günlük SEO ekonomisinin tam anlamıyla içinde yer aldığı ve diller arasında amaç açısından aynı olduğu için seçilmiştir.
- Sant Jordi hakkında bir kültürel-gelenek sorgusu; açık bir yerel otoriteye (bölgesel hükümet, belediye otoriteleri), düşük politik sıcaklığa ve belirli bir markadan bağımsız olarak yüzyıllarca belgelenmiş bir tarihe sahip olduğu için seçilmiştir.
- Katalan kiralama sübvansiyonlarına ilişkin düzenleyici bir sorgu; aşırı yerel yargı hassasiyeti gerektirdiği ve doğrudan Generalitat de Catalunya tarafından yönetildiği için seçilmiştir.
- Yüzeyin girdiyi Katalanca olarak tanıyıp tanımadığını görmek için sıradan ve resmi Katalanca sorguların bir karışımı olan bir dil tanımlama stres testi.
Aşağıdaki bulgular istatistiksel kanıtlardan ziyade tekrarlanabilir varoluş kanıtlarıdır. Bu spesifik hatalar bugün bu spesifik platformlarda, bu spesifik yerden meydana geliyor ve herhangi bir uygulayıcı, bunları 15 dakikadan kısa bir sürede tekrarlayabilir.
Bu kalıpların genelleştirildiği yönündeki daha geniş iddia, Google Arama İrtibatı'nın üç yıl önce zımnen doğruladığı topluluk kanıtlarına ve son on yılda Katalanca ve diğer azınlık dillerinde çalışan uygulayıcıların yaşadığı deneyimlere dayanıyor.
Dört model ortaya çıktı. İlk üçü geri getirmeyi tanımlar. Dördüncüsü özdeşleşmeyi tanımlar ve diğer üçünü destekler.
Bulgu 1: Kelime dağarcığı ve kaynak çoğulluğu birbirinden ayrılıyor
Hem ChatGPT'ye hem de Google'ın Yapay Zeka Genel Bakışı'na Katalan bağımsızlığı etrafındaki ana argümanlar hakkında sorular sordum.
İspanyolcada her iki yüzey de 1978 Anayasası ve 2017 referandumunun hukuka aykırılığına dayanan yasal bir çerçeve üretti. Katalancada her iki yüzey de ön plandadırbir karar vermek(karar verme hakkı) veotomatik belirlemeNova Planta Kararnameleri sonrasında kurumların kaybına tarihsel referanslar içeren kavramsal bloklar olarak adlandırılmıştır.
Katalan çıktısı daha ideolojik değildi. Daha eksiksizdi. İspanyolca versiyonda bulunmayan çerçeveler de dahil olmak üzere bağımsızlık karşıtı argümanları korudu.
 İspanyolca ve Katalanca bağımsızlık sorgusu için Google AI Genel Bakışı'nın yan yana karşılaştırması, alıntı panelleri görünür
İspanyolca ve Katalanca bağımsızlık sorgusu için Google AI Genel Bakışı'nın yan yana karşılaştırması, alıntı panelleri görünür
Alıntılarda farklılık keskinleşiyor. İspanyolca Yapay Zeka Genel Bakışı BBC, Wikipedia (ES), Fundación Espacio Público ve France 24'ten alınmıştır. Katalan Yapay Zeka Genel Bakışı, BBC ve El País'den alıntı yaparken El Punt Avui, VilaWeb, Reddit r/catalunya ve Wikipedia'yı (CA) ekledi.
Aynı motor, aynı coğrafya, aynı soru. Dil dizesi tarafından tetiklenen, birbiriyle örtüşmeyen iki alma havuzu. Dil cevabı etiketlemiyor. Korpusu filtreliyor.
Bulgu 2: Ticari erişimde kaymalar var ve motor azınlık dilinden şüphe ediyor
İşlem çifti basitti:Millors'ın Barselona'daki otonom yarışları için jestleri/Barselona'da özerklik için en iyi geziler. Barselona'daki serbest çalışanlar için aynı şehirden iki dilde en iyi muhasebeciler.
ChatGPT, her iki versiyonda da büyük ölçüde aynı fiziki firmaları önerdi, ancak çevrimiçi sağlayıcılar farklılaştı: Katalan tepkisi Openges ve Gestasor'u ortaya çıkardı; İspanyolların tepkisi Gestoría Online ve Gestorum'da ortaya çıktı. Dijital öncelikli segment için aynı amaç, aynı coğrafya, iki paralel ticari evren.
Google'ın organik SERP'si daha belirgin bir bölünme gösterdi. Katalan versiyonu yerel olarak iki dilli siteleri (Gremicat, Calders Assessors, Gestumm, barcelona.cool) yükseltti. İspanyolca versiyonu toplayıcılar ve genel dizinlerle (Legify, Zaask, bcngest) öncülük ediyordu.
İki ikincil sinyal sıralamalardan daha önemlidir.
İlk olarak Google, Katalanca sorguyu otomatik olarak düzeltti. Sonuçların üzerinde motor şunları sundu:Kısa Açıklama: Millors'un Barselona'daki Otonomları İçin Kazandıkları. Dondurma dükkanlarını mı kastettiniz? Barselona'daki bir IP üzerinde oturan sistem, Katalanca'daki ticari bir sorgunun gerçek olduğuna inanmayı reddetti ve sesteş sese bitişik bir alternatif önerdi.
 Otomatik düzeltmeyi gösteren Google SERP "Quizás quisiste decir: Millors gelateries per a autonoms a Barcelona"
Otomatik düzeltmeyi gösteren Google SERP "Quizás quisiste decir: Millors gelateries per a autonoms a Barcelona"
İkincisi, İspanya sonuçlarında ücretli reklamlar yer alıyordu: Talenom, Declarando, Horus Firm. Katalan sonuçları sıfırdı. SEM pazarı Katalanca'yı teklif verenlerin olmadığı bir bölge olarak görüyor ve ticari bir sinyalin olmayışı da başlı başına bir sinyal. Tıklama ve etkileşim verileri üzerine eğitilen modeller, bu yokluğu, dilin ticari açıdan ciddi olmadığının ve buna göre ağırlık kazanımının kanıtı olarak okuyor.
Mekanizma kendi kendine öğretir. Daha az ticari teklif, daha az ticari görünürlük sağlar. Daha az ticari görünürlük, daha az ticari sinyal üretir.
Her ne kadar Barselona'da Katalanca yazan her kullanıcı, İspanyolca yazan kullanıcıyla aynı coğrafyayı paylaşıyor olsa da, dilin işlemsel amaç açısından öncelikleri giderek azalıyor. Dil kimliğinin kendisine baktığımızda bu durum yeniden önem kazanacaktır.
Daha derine inin:AI araması, hreflang'ın ötesinde pazar uygunluğunu nasıl tanımlar?
Bulgu 3: Kültürel otorite yeniden atanıyor
Sant Jordi çifti bunu en açık şekilde gösteriyor ve spesifik yeniden atama, seanslar arasında kendini açıklayıcı bir şekilde değişiyor.
İlk oturumda, İspanyolca dilinde Yapay Zekaya Genel BakışSant Jordi GelenekleriAna alıntı olarak iki otel zinciriyle liderlik ediyor: Casa Llimona Hotel Boutique ve Sumus Hotels. Katalan versiyonunda, geleneği yüzyıllardır resmi olarak koruyan belediye meclisi olan Ajuntament de Barcelona'dan bahsediliyordu.
Bir hafta sonraki ikinci oturumda aynı sorgular farklı bir yeniden atama döndürdü. İspanyolca versiyonda artık yabancı ziyaretçilere yönelik devlet turizm portalı Spain.info'nun yanı sıra Ajuntament'ten de bahsediliyor. Katalan versiyonu kurumsal hiyerarşiyi tamamen yukarı taşıdı; birincil alıntısı bölgesel hükümet olan Generalitat de Catalunya oldu ve bir altbilgi bağlantısıyla birlikteKatalonya Generalitat'ı Diada'nın Resmi Guia'sı. Ajuntament yoktu.
 Bileşik — Her iki oturumda da Sant Jordi geleneklerine yönelik Google AI Genel Bakış alıntı panelleri, alıntı yapılan otoritelerdeki dile bağlı değişimi gösteriyor
Bileşik — Her iki oturumda da Sant Jordi geleneklerine yönelik Google AI Genel Bakış alıntı panelleri, alıntı yapılan otoritelerdeki dile bağlı değişimi gösteriyor
Her iki oturumda da sabit kalan şey yapısal kalıptır: Sistemin itibar ettiği kültürel koruyucu dille birlikte değişir. Katalan dilindeki sorular, geleneğe özgü kurumlar olan bölgesel ve belediye yönetimlerini gün yüzüne çıkarıyor. İspanyolca dilindeki sorgular, devlet turizmini, ticari varlıkları veya belediye yönetimini turistik bir destinasyon olarak çerçeveliyor.
ChatGPT düzyazısında aynı modeli güçlendiriyor. İspanyolca versiyonu Sant Jordi'yi dışarıdan tanımlıyor:Día del amor "a la catalana" Katalan kültürel mirasıyla tanışma fırsatı. Katalan versiyonu, mesafe olmaksızın yerel terminolojiyi kullanır. 600 yıllık aynı gelenek, bir dilde dışarıdan egzotik, diğerinde ise içeriden gelenek olarak tanımlanıyor.
Model her iki dilde de yalan söylemiyor. Geri alma havuzu göz önüne alındığında istatistiksel olarak en makul sentezi üretiyor. Ancak erişim havuzunun kendisi dil tarafından farklı şekilde oluşturuluyor; bir anayasa hükümeti kültürel koruyucu olarak ele alırken, diğeri turizm pazarlamasını kültürel koruyucu olarak görüyor.
Markalar için bu bir çeviri sorunu değil. Bu, modelin cevabın sahibi olduğunu düşündüğü sorudur.
Bulgu 4: Dil tanımlaması, Yüksek Lisans'lara dokunmadan önce zaten bozulmuştu
Geri kalanını yeniden çerçeveleyen bulgu budur. Yeniden atama kalıpları her şeyden önce sistemin sorgunun dilini ilk etapta doğru şekilde tanımlamasına bağlıdır. Çoğu zaman öyle değil.
Google Çeviri bulgusu (Katalanca'nın Barselona IP'sinden yanlışlıkla Oksitanca olarak sınıflandırılması) bunun bir yüzü. Bir diğeri ise Google Arama'ya açıkça Katalanca olan bir sorgu yazdığınızda olan şeydir.
SorguCalçots'un alıcıları— yalnızca Katalonya'da bulunan ve Katalanca adını diğer tüm dillerde koruyan bir sebze olan calçot tarifleri — sonuçların üzerinde bir pankart oluşturur:Öneriler: İspanyolca sonuçların çoğu. Daha fazla bilgi için, dil filtresinden yararlanabilirsiniz.Bu ekibin büyük bir
Sistem, kullanıcının Katalanca filtreleme sonuçlarını ortaya çıkarmasını önerir. Sorgu için AI Genel Bakışı oluşturulmaz. Altyapı, Katalanca'da yalnızca Katalanca olan bir sebze için yapılan tarif aramasının İspanyolca olarak daha yararlı bir şekilde yanıtlanmasına karar verdi.
 Google Arama, "receptes de calçots" sorgusu için "Sugerencia: Mostrar resultados en español" önerisini gösteriyor
Google Arama, "receptes de calçots" sorgusu için "Sugerencia: Mostrar resultados en español" önerisini gösteriyor
Google'ın AI Genel Bakışı'nda sorguSant Jordi'nin GelenekleriBazen tamamen Katalanca yazılmış olmasına rağmen, Spain.info'ya atıfta bulunarak İspanyolca yanıt verir. Diğer oturumlarda aynı sorgu Katalancada doğru şekilde tanımlanıp yanıtlanıyor.
Davranışın oturumlar arasında tutarsız olması, sürekli yanlış olmasından daha kötüdür: Teşhis edilemez. Bir site sahibi, sistemin ortaya çıkmaması nedeniyle aralıklı olarak bozulan bir şeyi düzeltemez.
Başarısızlık evrensel değildir. Gibi sorgularKatalonya şenlikleriveya poetes catalans contemporanis- biraz daha resmi veya bilgilendirici ifadeler - doğru bir şekilde Katalanca olarak tanımlanır ve bölgesel kaynaklara (Pimec, Gencat, El Temps, Lletra UOC) atıfta bulunularak Katalan dili senteziyle yanıtlanır.
Sistem Katalancayı tanımlayabiliyor. Ticari veya popüler sorgular için bunu güvenilir bir şekilde yapmaz; yanlış anlamanın maliyeti site sahipleri için en yüksek olanıdır.
Bulgular 2 ve 4'ün bir döngüyü kapattığı yer burasıdır. Katalanca'da sıfır SEM teklifi gösteren aynı ticari kategoriler, dil tanımlamanın en sık başarısız olduğu kategorilerdir. Ticari sinyali olmayan bir dil, sisteme ticari olarak ciddi bir dil olarak ele alınması gerekmediğini öğretir ve böylece ticari sorgular için sistem, kendisini daha az güvenilir bir şekilde tanımlamasına izin verir. İki başarısızlık birbirini güçlendiriyor.
Bunların hiçbiri yeni değil. Google Arama İrtibatı, Ocak 2023'te Katalan sıralamasının düşürülmesi sorununu kamuya açık bir şekilde kabul etti ve aynı yılın ilerleyen dönemlerinde klasik SERP'lerde gözle görülür iyileştirmeler sağladı.
Artık en üstte bulunan sentez katmanı bu düzeltmeleri miras almamıştır. Yapay zeka araması bu ardışık düzenler üzerine kuruludur. Varsayılanlarını, eğitim verileri kompozisyonlarını ve bir dilin ne zaman yanıtın dili olarak ele alınmayı hak ettiğine ilişkin kararlarını miras alır.
Azınlık dillerinde eğim döngüsü kapanıyor
İkinci, daha yavaş bir mekanizma, zamanla tüm bunları daha da kötüleştirir ve başka yerlerde görülmeye başlaması nedeniyle işaretlenmeye değer.
Web ölçeğinde bütünleşik eğitim almış yüksek lisans öğrencileri artık azınlık dillerinde hem doğrudan (çeviri özellikleri yoluyla) hem de dolaylı olarak (SEO içeriği, sosyal paylaşımlar ve otomatik makaleler üreten alt araçlar aracılığıyla) önemli miktarda düşük kaliteli içerik üretiyor.
Oluşturulan içerik dizine eklenir, taranır ve yeni nesil eğitim verilerine geri beslenir. Katalanca'yı iyi anlamayan model, bir sonraki modeli eğiten Katalanca içerik üretiyor.
Bu teorik değil. A2024 Princeton araştırmasıBrooks, Eggert ve Peskoff tarafından yapılan bir araştırma, yeni oluşturulan İngilizce Vikipedi makalelerinin %5'inden fazlasının yapay zeka tarafından oluşturulduğuna dair işaretler gösterdiğini ve Almanca, Fransızca ve İtalyanca baskılarda daha düşük ancak yine de ölçülebilir oranların olduğunu buldu.
Buna ek olarak - Princeton ekibinin ölçüm kapsamı dışında olsa da - daha ince bir editoryal denetime sahip azınlık dili baskılarının daha büyük bir orantılı etkiyi absorbe etmesi muhtemeldir.
Azınlık dilindeki hasar artık iyice belgelenmiştir. MIT Technology Review Eylül 2025'te şunları bildirdi:Dilsel “kıyamet döngüsü”savunmasız dildeki Vikipedi'lerde.
- Afrika dilindeki dört baskı üzerinde çalışan gönüllüler, makalelerinin %40 ila %60'ının düzeltilmemiş makine çevirileri olduğunu tahmin ediyor.
- İnuitçe baskısı, önemli sayfaların üçte ikisinden fazlasında makine tarafından çevrilmiş kısımlar içeriyordu.
- Hawaii dilindeki bazı girişlerin kelimelerinin %35'i anadili İngilizce olan kişiler tarafından anlaşılmaz olarak işaretlendi.
- Gerçek konuşmacılar tarafından neredeyse hiçbir makalenin yazılmadığı Grönlandca baskısının, Vikipedi Dil Komitesi'nin "dili yanlış sunabilecek sıklıkla saçmalık üreten" yapay zeka araçlarına atıfta bulunmasıyla, 2025'te kapatılması önerildi.
Wikipedia'nın 2022 yılında, kaynakları yetersiz olan 27 dil için kolayca erişilebilen tek çevrimiçi dil verisi kaynağı olduğu tahmin ediliyordu; bu, bu hataların Wikipedia'da kalmayacağı anlamına geliyordu. Yapay zeka sistemleri daha sonra bunlar üzerinde eğitim alıyor.
Bu döngüdür. Kötü dil tanımlaması kötü erişime neden olur. Kötü erişim, kötü içeriği ortaya çıkarır. Kötü içerik, dili tam olarak anlamayan Yüksek Lisans'lar tarafından geniş ölçekte üretiliyor. Kötü içerik indekslenir. Bir sonraki model bunun üzerinde çalışıyor.
Mekanizmanın kaliteyi düşürmek için kötülüğe ihtiyacı yok; yalnızca hacme ihtiyacı var. Azınlık dillerinde hacim oluşturmak hiç bu kadar kolay olmamıştı.
Vikipedi bu konuda ne yapmaya karar verdi?
Bu sorunun gerçek olduğuna dair en açık kurumsal sinyal, sorunu ciddiye alma konusunda hem deneyime hem de teşvike sahip birkaç platformdan birinden geliyor.
20 Mart'ta İngilizce Vikipedi topluluğu, 7,1 milyon makalesinde Yüksek Lisans tarafından oluşturulan makale içeriğinin yasaklanması yönünde resmi olarak oy kullandı. Editörlerin, temel kopya düzenleme ve diğer dillerdeki basımlardan makalelerin denetimli çevirisi için Yüksek Lisans'ı kullanmalarına hâlâ izin verilmektedir, ancak Yüksek Lisans'larla makale içeriği oluşturmak veya yeniden yazmak tamamen yasaktır.
Karar, yıllardır artan endişeye bir yanıttı: ChatGPT dönemi makaleleri, metinde bırakılan "geniş bir dil modeli olarak" istemiyle, tamamen var olmayan alıntılarla ve hakemlerin gönüllü olarak orantısız zaman harcadığı akıcı ama boş bir düzyazıyla görünüyordu.
Vikipedi tipik bir SEO endişesi değildir. Güçlü gönüllü yönetimine ve açık tarafsızlık politikalarına sahip, özenle seçilmiş bir bilgi platformudur. Düşük kaliteli içeriğe karşı bu düzeyde yapısal savunmaya sahip bir platform, yapay zeka tarafından oluşturulan metnin bilgi bütünlüğüne zarar verdiği sonucuna varırsa, SEO endüstrisi, Vikipedi'nin aşağısındaki erişim boru hatlarının, Vikipedi'nin yayınlamaya istekli olduğundan daha iyi yanıtlar üreteceğini varsaymamalıdır.
Azınlık dillerinde yapay zeka tarafından oluşturulan içeriğe karşı savunma oluşturan kurumlar (Wikipedia, Katalonya'daki Aina Projesi, Bask Ülkesindeki Latxa modelleri) ideolojik nedenlerden dolayı savunma yapmıyor. Kalitede ölçülü bir bozulmaya tepki veriyorlar. Bu bozulma artık yeni nesil yapay zeka aramasının eğitim verilerinin bir parçası.
Daha derine inin:Uluslararası SEO'yu geliştirmek için Google ve LLM içgörüleri nasıl kullanılır?
Bu neden oluyor, mekanik olarak
Motoko AvıAI sistemlerinin dili pazarlar için bir vekil olarak ele alarak coğrafi sınırları nasıl çökerttiğini belgeledi; bu olguya coğrafi kimlik sapması adını veriyor. Mekanizma burada da aynı, ancak onu daha net ortaya koyan ekstra bir kısıtlama var.
İki dil aynı coğrafyayı paylaştığında sistem sessizce varsayılan olarak "dilin ait olduğu ülkeyi" kullanamaz. Başka bir şeyi seçmek zorunda kalıyor. Seçim genellikle hangisi daha büyük, daha yeni veya daha ticari olarak etiketlenmişse ona gider.
Walker ve Timoneda'nın yukarıdaki çalışması bunu ampirik olarak temellendirdi. Bağımsızlık karşıtı çerçevelerin İspanya'da Katalanca'ya göre kabaca iki kat daha sık ortaya çıktığı bulgusu siyasetle ilgili bir bulgu değildi. Bu, eğitim verisi kompozisyonunun çıktıyı nasıl belirlediğine dair bir bulguydu. Eğitim külliyatındaki Katalanca metinler tek bir bakış açısı dağılımı taşır; İspanyolca metinler başka bir tane daha taşır. Model, şu anda ulaşmakta olduğu yüzeylerin her ikisini de devralır.
Bu, araştırmacıların dediği şeyle birleşiyoranlamsal çöküş: Geri alma yerleştirmeleri ulusal altı sinyalleri güvenilir bir şekilde ayıramadığında, sistem onları baskın değişkene göre düzleştirir. Tek dilli ülkelerde baskın değişken ülkenin kendisidir. Katalonya gibi bir bölgede baskın varyant, daha büyük dil komşusu olan İspanya'dır ve açık bir geri çekilme olmadığı sürece Katalancaya özgü anlamı genel bir İspanyolca varsayılanına doğru çeker.
Yerel yönetimler bunu fark etti. Aina Projesi ve Latxa modelleri münferit çabalar değil: bunlar dil-kaynak egemenliğini inşa etmeye yönelik doğrudan girişimlerdir çünkü standart küresel yüksek lisans eğitimleri Katalanca ve Baskça'da İspanyolca'ya göre ölçülebilir derecede daha kötü performans göstermektedir. Hükümetler kendi LLM'lerini eğitmeye başladığında, SEO endüstrisi bunu altta yatan mekanizmanın gerçek ve yapısal olduğunun kanıtı olarak ele almalıdır.
Desen Katalonya'ya özgü değil.
- Fransızca sorgulama yapan Quebec kullanıcıları, rutin olarak Paris-Fransız varsayılanlarını ve Quebec'in kendine özgü medeni kanunu ve eyalet vergi rejimi yerine Fransız düzenleyici çerçevelerine dayalı yanıtları alıyor.
- Belçikalı kullanıcılar, üç bölgesi gerçekten farklı hukuk ve dil kuralları altında faaliyet gösteren bir ülkede Fransız ve Hollanda yargısal varsayılanlarını karıştırıyor.
- İsviçreli kullanıcılar, geri almanın İsviçre'nin kendi sözleşmelerinden ziyade Alman veya Fransız ulusal temerrütlerine doğru düzleştiğini görüyor.
Katalan örneği, tek bir IP'den tek bir oturumda test edilmesi en kolay örnektir ancak yapısal bulgu, iki veya daha fazla dilin aynı coğrafyayı paylaştığı her bölgeye genellenir.
Öncü gösterge argümanı
İlginç olan soru bunun Katalonya için ne anlama geldiği değil. Katalonya'nın herkes için anlamı bu.
Çok dilli bölgeler kanaryalardır. İki dil aynı coğrafyayı paylaştığında ortaya çıkan mimari kusur (yargı yetkisini anlamdan güvenilir bir şekilde ayıramayan, zaten işleri yanlış anlayan bir dil tanımlama katmanının üstünde yer alan bir vektör alanı), yapay zeka araştırması olgunlaştıkça ve gerçekten ulus-altı yanıtlar denedikçe başka biçimlerde ortaya çıkacak.
Paralelliğe dikkat etmek istediğim yer burası. Tek dilli pazarlarda yapay zeka araması, Katalan örneğinin kısmen ortadan kaldırdığı yerelleştirme sinyallerine erişebilir: IP coğrafi konumu, GPS bağlamı, tarayıcı yerel ayarı ve yapılandırılmış yerel paket verileri.
Austin'den yüklenici lisanslarına ilişkin bir sorgu, sistem için Barselona'dan Katalanca bir sorgu kadar belirsiz değildir çünkü sistemin dayanabileceği daha fazla dil dışı bağlam vardır. Katalonya-Teksas paralelliği doğrudan bir eşdeğerlik değildir.
Yine de test etmeye değer bir hipotez. Katalancayı İspanyolcaya düzleştiren aynı mekanizmalar (tümce ağırlığı varsayılanları, anlamsal çöküş, eğitim-veri kompozisyonu), dil çiftinden bağımsız olarak sentez ardışık düzenlerinde mevcuttur.
AI Genel Bakışları ve sohbet tarzı arama, sorguları yerelleştirilmiş bağlantıları ortaya çıkarmak yerine giderek daha fazla sentez yoluyla yanıtladıkça, IP tabanlı yerelleştirmenin koruyucu etkisi zayıflar. Sistem hangi derlemin "cevabı" temsil ettiğine dair bir karar vermek zorundadır ve derlem ağırlığı kazanma eğilimindedir.
Bunun tek dilli İngiliz pazarlarında ortaya çıkma ihtimalinin en yüksek olduğu yerler: Önemli külliyat asimetrisine sahip eyalet düzeyindeki düzenlemeler. Kaliforniya'nın CCPA'sı ve Teksas'ın veri gizliliği rejimi aynı dilde yazılmıştır ancak farklı yargısal gerçeklikleri temsil etmektedir.
Gizlilik literatürü ağırlıklı olarak Kaliforniya ağırlıklıdır. Yapay Zeka Genel Bakışı genel bir "hangi gizlilik haklarına sahibim" yanıtını sentezlediğinde, varsayılanlar hangi yargı yetkisinin daha fazla yetki sinyaline sahip olduğuna yönelir. Yerelleştirme yardımcı olur, ancak yalnızca sorgunun kendisi yargı açısından açık olduğunda.
Herhangi bir büyük ülkede alt-ulusal düzenleyici ayrıntı düzeyi. İçki ruhsatı, müteahhit lisansı, gayrimenkul ifşa kuralları, nafaka hesaplamaları, okul bölgesi politikaları, imar kodları; yargı bölgelerine özel, tamamı İngilizce, yargı bölgeleri arasında son derece farklı külliyat ağırlıkları var. Daha fazla sorgu, bağlantılardan ziyade sentez yoluyla yanıtlandıkça, yargısal varsayılanlar, geleneksel SEO'nun hiçbir zaman endişelenmesine gerek kalmayacak şekilde sonuçsal hale gelir.
Bunu abartmak istemiyorum. Temiz Katalan gösterisinin Teksas'ta doğrudan tekrarlanması mümkün değil. Tekrarlanabilir olan, altta yatan gözlemdir: Erişim sistemi sinyalleri çökerttiğinde, onları daha büyük, daha iyi temsil edilen bir külliyat lehine çökertir. Çöken sinyallerin dilsel, yargısal veya her ikisi de olması fark etmez, bu doğrudur.
İspanya ve Meksika'da nasıl faaliyet göstereceklerini çözen markalar bu dersin bir versiyonunu zaten öğrenmiş durumda. Teksas ve Kaliforniya'da faaliyet gösteren markalar muhtemelen aynı görünmeyecek ve kendi teşhisini gerektirecek bir biçimde ilgili bir tane öğrenecek.
Bu konuda ne yapmalı
Çok dilli parçalanma için işe yarayan ilkeler, uyarlamayla birlikte çok yargı yetkisine sahip parçalanmaya aktarılır. Aynı ilaç ailesi, farklı hasta.
Ulusal altı yargı yetki alanlarını ayrı kuruluşlar olarak ele alın. İşletmeniz birden fazla ABD eyaletinde düzenlenmiş dikeylerde faaliyet gösteriyorsa, bu eyalet sürümlerinin yalnızca bir klasör yapısına değil, kendi yetki sinyallerine de ihtiyacı vardır. Her değişken, çöküşe davetiye çıkaracak ulusal bir ana sayfaya değil, kendisine göre standartlaştırılmalıdır.
Yetki alanını açıkça yapılandırılmış verilerde kodlayın ve kopyalayın. Schema.org'unHizmet verilen alanherhangi bir coğrafi ayrıntı düzeyinde çalışır; bunu önemli olan eyalet, ilçe veya belediyeye kadar kullanın. Bunu açık kopya işaretleyicileriyle eşleştirin: düzenleyici adları, duruma özgü tanımlayıcılar, bölgeye özgü para birimleri veya formatlar. Modelin deterministik kancalara ihtiyacı var. Onlar olmadan doğaçlama yapar.
Wikidata aracılığıyla ulus-altı temelleri güçlendirin. Çoğu SEO programı site içi şemada durur, ancak bilgi grafikleri diğer grafiklerin sizin hakkınızda söylediklerini okur. Vikiveri'nin yetki alanı mülkü (P1001) ve açık dil özellikleri, yetki alanı ve dil sınırlarını bilgi grafiği düzeyinde (tam olarak yapay zeka sistemlerinin varlık bağlamını çektiği katman) kodlamanıza olanak tanır. Ticari açıdan önemli olan yerel bir yargı bölgesinde faaliyet gösteriyorsanız, kuruluşunuz orada önemli olan ayrıntı düzeyiyle modellenmelidir.
Ulus-altı otorite boşluklarını denetlemek, uluslararası olanları denetlemekle aynı şekildedir. İspanya - Meksika, ancak Teksas - Kaliforniya veya Kanada'da Ontario - Quebec veya işletmenizin faaliyet gösterdiği herhangi bir yargı bölgesi için çalıştıracağınız teşhis istemlerini çalıştırın. Model bunları birleştiriyorsa içeriğinizin tek bir pazar gibi görünen bir yerde parçalanma sorunu var demektir.
İkincil sinyalleri izleyin. Katalanca'da SEM tekliflerinin yokluğu bir sinyaldi ve sistem bundan ders aldı. Aynı durum, yetersiz hizmet verilen tek dilli yargı bölgeleri için de geçerlidir: Eğer hiç kimse Teksas'a özgü terminolojiye teklif vermezse, Teksas'a özgü içeriğin sentezde öncelikleri ortadan kalkar. Bilgi grafiği varlığınız, yerel alıntılarınız ve otorite sinyallerinin tümü baskın yargı yetkisine işaret ediyorsa, modelin yeterince temsil edilmeyen modeli ortaya çıkarmak için hiçbir nedeni yoktur.
Bu yeni bir taktik kitabı değil. Bukültürel SEO çerçevesiülke sınırının altında uygulanır: pazar bölümleme, yaratıcılığa dayalı olma, erişim kısıtlamaları ve varlık güçlendirme, ancak ulus altı ayrıntı düzeyinde.
Bunun yapay zeka arama stratejiniz açısından anlamı nedir?
Sant Jordi'nin yanıtı kötü çeviri yüzünden başarısız olmadı. Başarısız oldu çünkü çevirinin altındaki dil tanımlama katmanı Katalancayı Oksitancadan, Katalancayı İspanyolcadan veya sorgu dili Katalancasını alakasız gürültü olarak Katalancadan hiçbir zaman tutarlı bir şekilde ayırmadı.
Google bunu üç yıl önce Katalanca'da kendisi söyledi. Bu katmanın üzerine inşa edilen erişim hattı, bu kararların her birini devralır ve şimdi bunları sessizce yayan sentezlenmiş yanıtlar üretir.
Aynı üretken yapay zeka ekosistemine farklı bir açıdan bakan Wikipedia, Mart 2026'da bozulma riskinin Yüksek Lisans tarafından oluşturulan içeriği tamamen yasaklayacak kadar ciddi olduğuna karar verdi. Aina Projesi ve Latxa ekibi, kendi temel modellerini finanse ederek aynı sonuca önceden ulaştı. Çok dilli bilgi bütünlüğüne en yakın kurumlar genel yapay zekadan uzaklaşıyor. SEO endüstrisi en azından bu modeli fark etmelidir.
Çok dilli bölgeler, yapay zeka aramasında yer alan yapısal bir varsayımı ortaya koyuyor: dil ve pazarın aynı şey olduğu ve dilin bir sorgu dizesinden güvenilir bir şekilde bilinebildiği. İkisi de doğru değil. Hreflang, coğrafi ayrımı geleneksel arama için işlevsel hale getirdi. Henüz hiçbir şey onu üretken erişim için çalışır hale getirmedi.
İspanya ve Meksika'da iyi faaliyet gösteren markalar, bunu diller için nasıl düzelteceklerini zaten biliyor. Aynı teknikler (açık yetki sinyalleri, pazara özgü otorite, bilgi edinme kısıtlamaları, çeviri yerine yaratıcı çeviri, bilgi grafiklerinde varlık temeli) artık herhangi bir dil kombinasyonunda herhangi bir yetki çiftinde iyi bir şekilde işleyebilmek için masada yer alıyor.
Birden fazla yargı bölgesinde faaliyet gösteriyorsanız sorulması gereken soru içeriğinizin yerelleştirilmiş olup olmadığı değildir. Modelin bunu anlayıp anlayamadığı.

